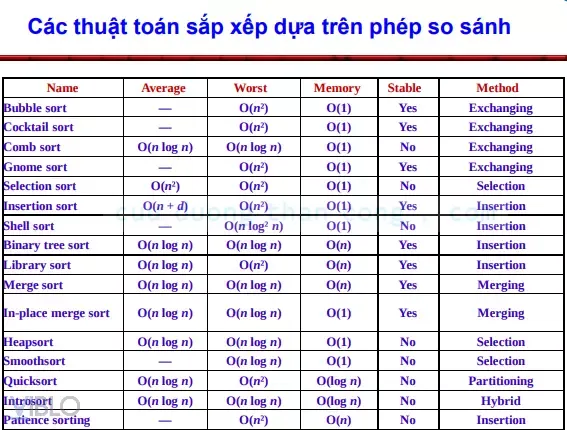
Trong khoa học máy tính, việc tổ chức dữ liệu là nền tảng cốt lõi để xây dựng các ứng dụng hiệu năng cao, và các thuật toán sắp xếp chính là những công cụ cơ bản nhất trong bộ kỹ năng của mọi kỹ sư phần mềm chuyên nghiệp. Tối ưu hóa thứ tự lưu trữ không chỉ giúp dữ liệu trở nên dễ đọc hơn mà còn là tiền đề để triển khai các thuật toán tìm kiếm (như Binary Search) với độ phức tạp cực thấp. Bài viết này sẽ phân tích chuyên sâu từ nguyên lý, mã nguồn thực thi đến đánh giá hiệu năng thực tế của các giải pháp sắp xếp phổ biến hiện nay.
Bản chất kỹ thuật của bài toán sắp xếp
Trước khi đi vào chi tiết, chúng ta cần thống nhất về định nghĩa kỹ thuật. Bài toán sắp xếp (Sorting problem) yêu cầu chuyển đổi một dãy đầu vào $A = (a_1, a_2, …, a_n)$ thành một hoán vị $A’ = (a’_1, a’_2, …, a’_n)$ sao cho $a’_1 le a’_2 le … le a’_n$ (đối với sắp xếp tăng dần).
Trong thực tế, một lập trình viên Senior không chỉ nhìn vào tốc độ (Time Complexity) mà còn phải xem xét hai yếu tố then chốt:
- Tính ổn định (Stability): Một thuật toán được gọi là ổn định nếu nó giữ nguyên thứ tự tương đối của các phần tử có giá trị bằng nhau. Điều này cực kỳ quan trọng khi bạn sắp xếp các object phức tạp (ví dụ: sắp xếp danh sách hóa đơn theo ngày, sau khi đã sắp xếp theo số tiền).
- Khả năng sắp xếp tại chỗ (In-place): Thuật toán có tiêu tốn thêm bộ nhớ tỷ lệ thuận với kích thước dữ liệu hay không ($O(1)$ vs $O(n)$).
Hai phép toán nguyên tử tạo nên các thuật toán sắp xếp là:
- Phép so sánh (Comparison): Trả về giá trị Boolean.
- Phép hoán vị (Swap): Đổi chỗ hai phần tử trong bộ nhớ.
// Ngôn ngữ: C++17
// Hàm swap chuẩn hóa sử dụng reference để tối ưu bộ nhớ
template <typename T>
void professionalSwap(T &a, T &b) {
T temp = std::move(a); // Sử dụng move semantics của C++11+
a = std::move(b);
b = std::move(temp);
}
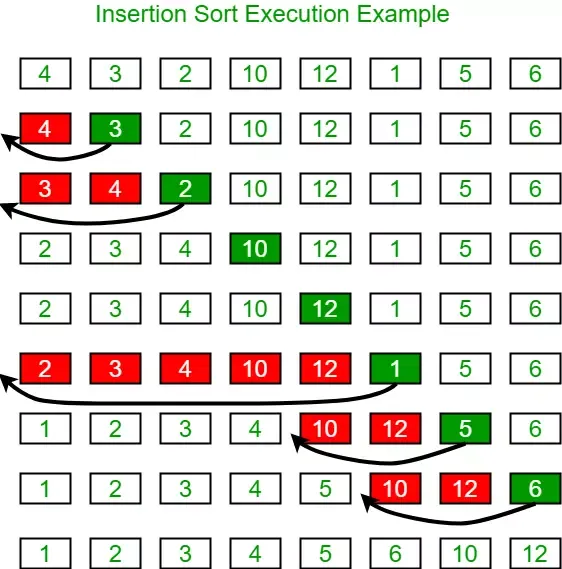
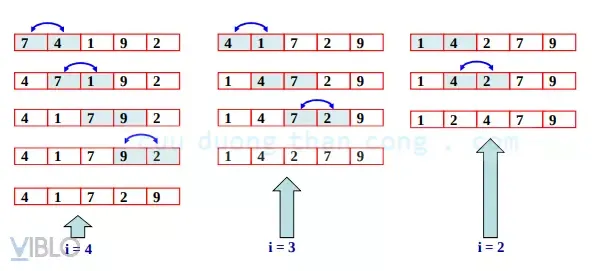
1. Thuật toán sắp xếp chèn (Insertion Sort)
Sắp xếp chèn mô phỏng cách chúng ta sắp xếp các quân bài trên tay. Ta bắt đầu với một quân bài và mỗi lần rút thêm một quân mới, ta tìm vị trí thích hợp để “chèn” nó vào dãy đã được sắp xếp trước đó.
Nguyên lý hoạt động
Thuật toán chia mảng thành hai phần: phần đã sắp xếp (bên trái) và phần chưa sắp xếp (bên phải). Duyệt từ phần tử thứ 2, ta so sánh nó với các phần tử bên trái để tìm vị trí đứng đúng.
Mã nguồn thực thi (C++17)
/
Insertion Sort Implementation
Version: C++17
/
#include <iostream>
#include <vector>
void insertionSort(std::vector<int>& arr) {
int n = arr.size();
if (n <= 1) return; // Edge case: mảng trống hoặc 1 phần tử
for (int i = 1; i < n; i++) {
int key = arr[i];
int j = i - 1;
// Di chuyển các phần tử lớn hơn key về sau 1 vị trí
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}
// Input: {5, 2, 9, 1, 5}
// Output: {1, 2, 5, 5, 9}Phân tích chuyên sâu
- Độ phức tạp thời gian: $O(n^2)$ trong trường hợp xấu nhất, nhưng đạt $O(n)$ nếu mảng đã gần như sắp xếp xong (Nearly Sorted). Đây là lý do vì sao trong các thư viện chuẩn như
std::sort, Insertion Sort được dùng cho các mảng con có kích thước cực nhỏ (thường < 16 phần tử). - Độ phức tạp không gian: $O(1)$ (In-place).
- Tính ổn định: Có (Stable).

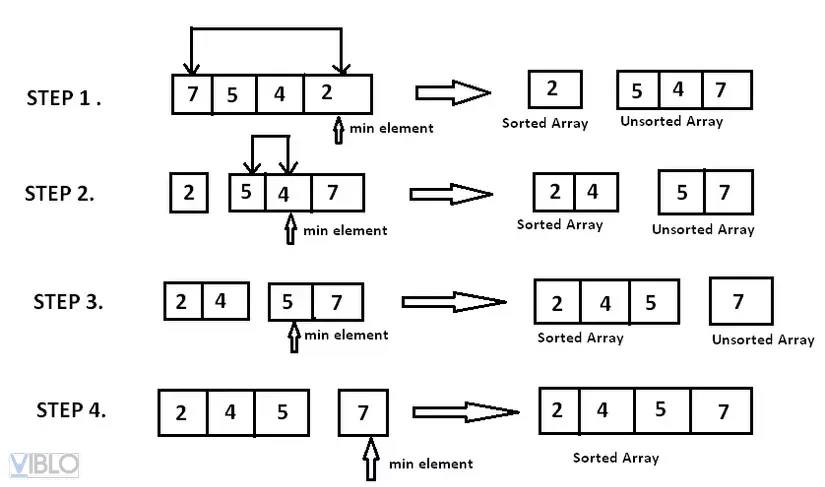
2. Thuật toán sắp xếp lựa chọn (Selection Sort)
Nếu Insertion Sort tập trung vào việc “chèn”, thì Selection Sort tập trung vào việc “tìm kiếm”.
Nguyên lý hoạt động
Ở mỗi bước, thuật toán tìm phần tử nhỏ nhất trong đoạn chưa sắp xếp và hoán đổi nó với phần tử đầu tiên của đoạn đó. Quá trình tiếp tục cho đến khi toàn bộ mảng được xử lý.
Mã nguồn thực thi (C++17)
/
Selection Sort Implementation
Optimization: Minimizing swaps
/
void selectionSort(std::vector<int>& arr) {
int n = arr.size();
for (int i = 0; i < n - 1; i++) {
int min_idx = i;
for (int j = i + 1; j < n; j++) {
if (arr[j] < arr[min_idx]) {
min_idx = j;
}
}
// Chỉ swap khi tìm thấy giá trị nhỏ hơn thực sự
if (min_idx != i) {
std::swap(arr[i], arr[min_idx]);
}
}
}Đánh giá từ kinh nghiệm thực tế
Selection Sort có một ưu điểm rất lớn là số lần swap tối thiểu ($O(n)$). Trong các hệ thống nhúng nơi việc ghi vào bộ nhớ (write operation) cực kỳ tốn kém hoặc gây hại (như Flash memory), Selection Sort đôi khi lại có giá trị hơn các thuật toán nhanh nhưng swap nhiều. Tuy nhiên, nó không ổn định và luôn chạy $O(n^2)$ bất kể dữ liệu đầu vào.
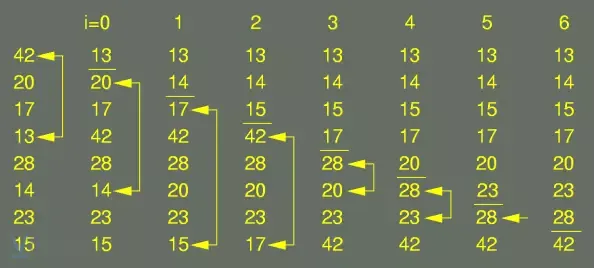
3. Thuật toán sắp xếp nổi bọt (Bubble Sort)
Đây là thuật toán “vỡ lòng” khi học về các thuật toán sắp xếp, nhưng trong môi trường Production, nó gần như không bao giờ được sử dụng do hiệu năng quá kém.
Nguyên lý hoạt động
Thuật toán so sánh các cặp phần tử liền kề và hoán đổi chúng nếu sai thứ tự. Sau mỗi lượt duyệt, phần tử lớn nhất sẽ “nổi” lên vị trí cuối cùng của mảng.
Mã nguồn tối ưu (C++17)
/
Optimized Bubble Sort
Thêm flag stop sớm nếu mảng đã sắp xếp
/
void bubbleSort(std::vector<int>& arr) {
int n = arr.size();
bool swapped;
for (int i = 0; i < n - 1; i++) {
swapped = false;
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
std::swap(arr[j], arr[j + 1]);
swapped = true;
}
}
// Nếu không có swap nào, mảng đã xong
if (!swapped) break;
}
}Pitfall cần tránh
Lỗi phổ biến của người mới bắt đầu là không sử dụng biến swapped. Nếu không có cơ chế dừng sớm, thuật toán sẽ luôn chạy $n^2/2$ phép so sánh ngay cả khi mảng đã sắp xếp xong, gây lãng phí tài nguyên CPU nghiêm trọng.
Bảng so sánh 3 thuật toán O(n²)
| Thuật toán | Best Case | Average Case | Worst Case | Space | Stability |
|---|---|---|---|---|---|
| Insertion Sort | $O(n)$ | $O(n^2)$ | $O(n^2)$ | $O(1)$ | Yes |
| Selection Sort | $O(n^2)$ | $O(n^2)$ | $O(n^2)$ | $O(1)$ | No |
| Bubble Sort | $O(n)$ | $O(n^2)$ | $O(n^2)$ | $O(1)$ | Yes |

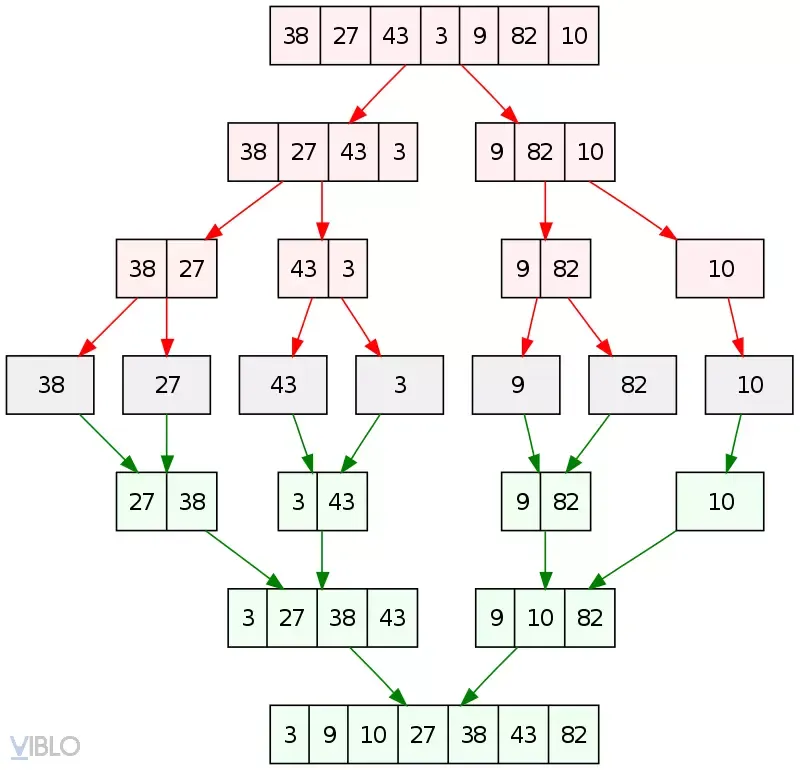
4. Thuật toán sắp xếp trộn (Merge Sort)
Merge Sort là đại diện xuất sắc cho tư duy “Divide and Conquer” (Chia để trị). Đây là một trong các thuật toán sắp xếp có hiệu suất ổn định nhất.
Tư duy thuật toán
- Chia: Chia mảng hiện tại thành hai mảng con cho đến khi mỗi mảng chỉ còn 1 phần tử.
- Trị: Một mảng có 1 phần tử mặc nhiên được coi là đã sắp xếp.
- Kết hợp: Trộn hai mảng con đã sắp xếp để tạo thành mảng mới lớn hơn cũng được sắp xếp.
Mã nguồn thực thi (Java 17+)
/
Merge Sort Implementation in Java 17
Demonstrates recursive approach and stability
/
public class ProfessionalSort {
public static void mergeSort(int[] arr, int left, int right) {
if (left < right) {
int mid = left + (right - left) / 2; // Tránh tràn số nguyên
mergeSort(arr, left, mid);
mergeSort(arr, mid + 1, right);
merge(arr, left, mid, right);
}
}
private static void merge(int[] arr, int left, int mid, int right) {
int n1 = mid - left + 1;
int n2 = right - mid;
int[] L = new int[n1];
int[] R = new int[n2];
System.arraycopy(arr, left, L, 0, n1);
System.arraycopy(arr, mid + 1, R, 0, n2);
int i = 0, j = 0, k = left;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) { // Dấu <= đảm bảo tính ổn định (stability)
arr[k++] = L[i++];
} else {
arr[k++] = R[j++];
}
}
while (i < n1) arr[k++] = L[i++];
while (j < n2) arr[k++] = R[j++];
}
}Phân tích hiệu năng
- Time Complexity: Luôn là $O(n log n)$ bất kể dữ liệu đầu vào. Điều này làm cho Merge Sort được sử dụng rộng rãi trong các hệ thống cần sự đảm bảo về thời gian phản hồi (Real-time systems).
- Space Complexity: $O(n)$ vì cần mảng phụ để chứa dữ liệu khi trộn.
- Ứng dụng thực tế: Được ứng dụng để sắp xếp danh sách liên kết (Linked List) vì nó không yêu cầu truy cập ngẫu nhiên (Random Access).
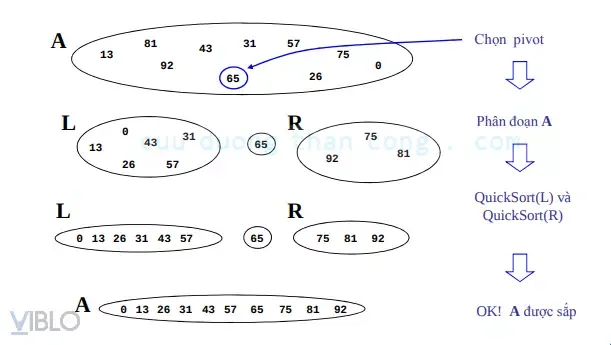
5. Thuật toán sắp xếp nhanh (Quick Sort)
Đúng như tên gọi, đây là thuật toán có tốc độ thực thi nhanh nhất trong thực tế nếu được cấu hình đúng cách. Hầu hết các thư viện hàm sort() của ngôn ngữ lập trình đều dựa trên biến thể của Quick Sort.
Cách thức hoạt động
Quick Sort chọn một phần tử làm “chốt” (pivot) và phân hoạch mảng sao cho các phần tử nhỏ hơn pivot nằm bên trái và các phần tử lớn hơn nằm bên phải. Sau đó lặp lại đệ quy cho hai nửa.
Chiến lược chọn Pivot (Kinh nghiệm chuyên gia)
Việc chọn pivot quyết định độ phức tạp của thuật toán:
- Chọn phần tử đầu/cuối: Dễ gặp Bad Case ($O(n^2)$) nếu mảng đã sắp xếp.
- Chọn ngẫu nhiên: Giảm thiểu rủi ro gặp Bad Case.
- Median-of-three: Chọn trung vị của 3 phần tử (đầu, giữa, cuối). Đây là Best Practice trong phát triển phần mềm.
Mã nguồn phân đoạn Partition (C++17)
/
Quick Sort with Median-of-three Pivot
/
int partition(std::vector<int>& arr, int low, int high) {
int mid = low + (high - low) / 2;
// Đưa pivot về cuối để thực hiện partition
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j < high; j++) {
if (arr[j] < pivot) {
i++;
std::swap(arr[i], arr[j]);
}
}
std::swap(arr[i + 1], arr[high]);
return (i + 1);
}
void quickSort(std::vector<int>& arr, int low, int high) {
if (low < high) {
int pi = partition(arr, low, high);
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}Điểm yếu cốt tử
Quick Sort không ổn định (Unstable). Nếu bạn cần sắp xếp các dữ liệu có nhiều thuộc tính dựa trên các thuật toán sắp xếp, bạn phải cân nhắc giữa tốc độ của Quick Sort và sự an toàn của Merge Sort.

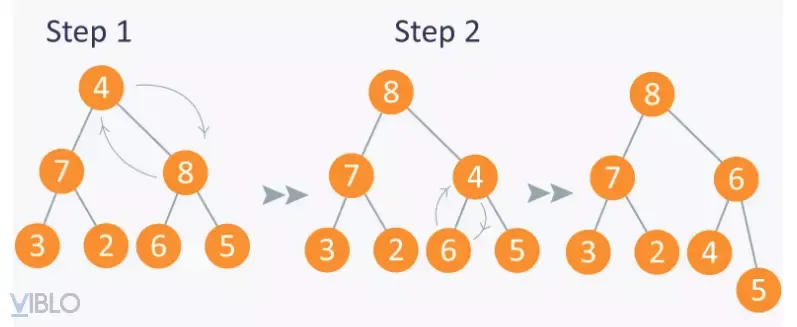
6. Thuật toán sắp xếp vun đống (Heap Sort)
Sắp xếp vun đống dựa trên cấu trúc dữ liệu Binary Heap. Đây là sự kết hợp hoàn hảo giữa tốc độ của Quick Sort và tính tiết kiệm bộ nhớ của Selection Sort.
Cấu trúc Max-Heap
Max-Heap là một cây nhị phân gần hoàn chỉnh, trong đó node cha luôn lớn hơn hoặc bằng các node con. Gốc của cây luôn chứa giá trị lớn nhất mảng.
Quy trình thực hiện
- Xây dựng Max-Heap từ mảng đầu vào ($O(n)$).
- Lấy phần tử gốc (lớn nhất) hoán vị với phần tử cuối cùng.
- “Vun lại đống” (Heapify) cho phần còn lại ($O(log n)$).
- Lặp lại cho đến khi mảng cạn kiệt.
Mã nguồn Heapify chuyên nghiệp (C++17)
/
Heapify function - Trái tim của Heap Sort
/
void heapify(std::vector<int>& arr, int n, int i) {
int largest = i;
int left = 2 i + 1;
int right = 2 i + 2;
if (left < n && arr[left] > arr[largest])
largest = left;
if (right < n && arr[right] > arr[largest])
largest = right;
if (largest != i) {
std::swap(arr[i], arr[largest]);
// Đệ quy để vun lại các đống con bị ảnh hưởng
heapify(arr, n, largest);
}
}
void heapSort(std::vector<int>& arr) {
int n = arr.size();
// Xây dựng heap ban đầu
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
// Trích xuất từng phần tử khỏi heap
for (int i = n - 1; i > 0; i--) {
std::swap(arr[0], arr[i]);
heapify(arr, i, 0);
}
}Tại sao nên dùng Heap Sort?
Heap Sort có độ phức tạp $O(n log n)$ trong mọi trường hợp (giống Merge Sort) nhưng lại là In-place (giống Selection Sort). Tuy nhiên, nó chậm hơn Quick Sort trong thực tế một chút vì không tận dụng được cơ chế Cache của CPU hiệu quả bằng.

Tổng kết và Lời khuyên thực tế
Việc nắm vững các thuật toán sắp xếp không chỉ áp dụng để “pass” phỏng vấn, mà còn giúp bạn đưa ra các quyết định kiến trúc đúng đắn. Trong dự án thực tế, bạn sẽ chọn thuật toán theo bộ tiêu chuẩn sau:
- Dữ liệu nhỏ (< 20 phần tử): Dùng Insertion Sort.
- Dữ liệu rất lớn, ưu tiên tốc độ: Dùng Quick Sort (nhưng cần kiểm tra chiến lược chọn pivot).
- Yêu cầu tính ổn định (Stability): Phải dùng Merge Sort hoặc Timsort (biến thể của Merge và Insertion).
- Hệ thống nhúng, bộ nhớ cực hạn: Dùng Heap Sort (In-place, $O(n log n)$).
- Dữ liệu gần như đã sắp xếp: Insertion Sort là vô địch.
Lưu ý quan trọng: Hầu hết các ngôn ngữ hiện đại đều sử dụng Timsort (như Python, Java) hoặc IntroSort (như C++ std::sort). IntroSort là sự kết hợp: bắt đầu bằng Quick Sort, nếu đệ quy quá sâu sẽ chuyển sang Heap Sort, và nếu mảng con quá nhỏ thì dùng Insertion Sort. Đây chính là cách tiếp cận hybird mà một lập trình viên cấp cao luôn hướng tới: không có công cụ tốt nhất, chỉ có công cụ phù hợp nhất với dữ liệu.
Hy vọng qua phân tích chi tiết này, bạn đã có cái nhìn thấu đáo về thế giới của các thuật toán sắp xếp. Ở bài viết tiếp theo, chúng ta sẽ đi sâu vào cấu trúc dữ liệu đồ thị và các bài toán tìm đường đi ngắn nhất.
Nguồn tham khảo:
- Cormen, T. H., Leiserson, C. E., Rivest, R. L., & Stein, C. (2009). Introduction to Algorithms.
- IEEE Standard for Floating-Point Arithmetic (IEEE 754).
- C++ Reference: Standard Algorithms library.
Cập nhật lần cuối 01/03/2026 by Hiếu IT