Trong kỷ nguyên dữ liệu lớn ngày nay, việc nắm vững các thuật toán tìm kiếm đóng vai trò then chốt để tối ưu hiệu năng phần mềm. Kỹ năng này giúp bạn giải quyết các bài toán truy xuất thông tin nhanh chóng dựa trên những cấu trúc dữ liệu phức tạp. Việc hiểu rõ bản chất toán học và độ phức tạp tính toán là điều kiện bắt buộc đối với một lập trình viên chuyên nghiệp. Bài viết này sẽ phân tích sâu các phương pháp tối ưu nhất để xử lý dữ liệu hiện nay.
Phân loại các thuật toán tìm kiếm phổ biến nhất
Việc phân loại giúp chúng ta có cái nhìn tổng quát trước khi đi sâu vào chi tiết triển khai mã nguồn cụ thể. Trong khoa học máy tính, các thuật toán tìm kiếm thường được chia làm hai nhóm chính dựa trên trạng thái của dữ liệu đầu vào. Nhóm thứ nhất không yêu cầu dữ liệu phải sắp xếp trước, điển hình là tìm kiếm tuyến tính với tính đơn giản cao. Nhóm thứ hai đòi hỏi dữ liệu đã qua xử lý sắp xếp để đạt được tốc độ truy xuất tối ưu hơn rất nhiều.
Hầu hết các thuật toán tìm kiếm hiện đại đều hướng tới việc giảm thiểu số lần so sánh phần tử trong bộ nhớ. Điều này giúp tiết kiệm tài nguyên CPU và rút ngắn thời gian phản hồi của hệ thống đối với người dùng cuối. Tùy thuộc vào quy mô của tập dữ liệu, chúng ta sẽ lựa chọn phương pháp triển khai phù hợp để đạt hiệu quả cao.
Thuật toán Linear Search trong các thuật toán tìm kiếm
Đối với các thuật toán tìm kiếm cơ bản, Linear Search hay tìm kiếm tuyến tính là điểm bắt đầu hoàn hảo cho mọi lập trình viên. Phương pháp này hoạt động bằng cách quét qua từng phần tử của danh sách từ đầu đến cuối cho tới khi tìm thấy. Nó không yêu cầu bất kỳ điều kiện tiên quyết nào về thứ tự của các giá trị bên trong cấu trúc mảng.
Nguyên lý hoạt động và phân tích kỹ thuật
Thuật toán thực hiện so sánh lần lượt giá trị cần tìm với từng phần tử trong mảng dữ liệu hiện có. Nếu tìm thấy sự trùng khớp, hàm sẽ trả về vị trí index tương ứng của phần tử đó trong bộ nhớ lưu trữ. Trong trường hợp đã duyệt hết toàn bộ danh sách mà không có kết quả, thuật toán sẽ trả về giá trị null.
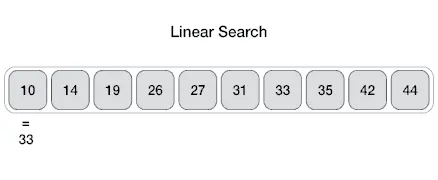
Dưới góc độ hiệu năng, Linear Search có độ phức tạp thời gian là O(n) theo ký pháp Big O tiêu chuẩn. Điều này có nghĩa là khi kích thước mảng tăng lên, thời gian tìm kiếm cũng sẽ tăng lên theo tương ứng. Đây là nhược điểm chí mạng khiến nó không phù hợp cho các hệ thống chứa hàng triệu bản ghi dữ liệu lớn.
Triển khai mã nguồn Python 3.10+ tối ưu
Dưới đây là cách triển khai hàm tìm kiếm tuyến tính bằng ngôn ngữ Python với đầy đủ các chú thích kỹ thuật chuyên sâu. Code được thiết kế theo dạng Generic để có thể làm việc với nhiều kiểu dữ liệu khác nhau trong danh sách.
from typing import List, Any, Optional def linear_search(data_list: List[Any], target: Any) -> Optional[int]: """ Thực hiện tìm kiếm tuyến tính trên một danh sách bất kỳ. Phiên bản: Python 3.10+ Args: data_list: Danh sách các phần tử cần tìm (mảng chưa sắp xếp). target: Giá trị mục tiêu cần xác định vị trí. Returns: Vị trí index đầu tiên tìm thấy hoặc None nếu không tồn tại. """ # Duyệt qua từng chỉ mục và giá trị trong danh sách bằng enumerate for index, value in enumerate(data_list): # Kiểm tra điều kiện bằng nhau của giá trị if value == target: return index # Trả về None nếu kết thúc vòng lặp mà không tìm thấy return None # Input mẫu numbers = [64, 34, 25, 12, 22, 11, 90] search_key = 22 # Output mẫu: 4 print(f"Vị trí của {search_key} là: {linear_search(numbers, search_key)}")Binary Search – Đỉnh cao của các thuật toán tìm kiếm
Khi làm việc với các hệ thống lớn, Binary Search thường được coi là tiêu chuẩn vàng trong các thuật toán tìm kiếm. Thuật toán này sử dụng chiến lược chia để trị cực kỳ mạnh mẽ để loại bỏ một nửa không gian tìm kiếm. Tuy nhiên, điều kiện bắt buộc để áp dụng thành công phương pháp này là bạn phải có một mảng đã sắp xếp.
Cơ chế vận hành theo mô hình chia để trị
Thay vì kiểm tra từng phần tử, Binary Search bắt đầu từ vị trí giữa của mảng dữ liệu đã được sắp xếp trước. Nếu giá trị ở giữa lớn hơn mục tiêu, chúng ta sẽ thu hẹp phạm vi tìm kiếm vào nửa bên trái. Ngược lại, nếu giá trị ở giữa nhỏ hơn, quá trình tìm kiếm sẽ tiếp tục dịch chuyển sang nửa bên phải.
Đầu tiên, chúng ta xác định chỉ số giữa theo công thức tránh tràn số trong các ngôn ngữ lập trình như C++.
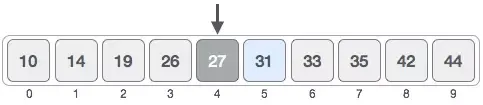
Quá trình so sánh giúp loại bỏ ngay lập tức 50% số lượng các phần tử không liên quan trong mỗi bước thực hiện.
Các bước này được lặp đi lặp lại một cách tuần tự hoặc thông qua tính chất đệ quy cho tới khi tìm thấy.
Phạm vi ngày càng được thu hẹp tối đa giúp tốc độ xử lý đạt tới ngưỡng cực nhanh trong thực tế lập trình.
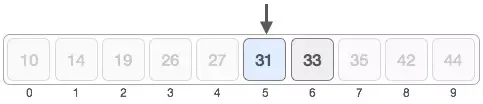
Khi giá trị tại chỉ mục mid trùng khớp với mục tiêu, chúng ta sẽ trả về kết quả cuối cùng cho hàm.
Hiệu quả hơn các thuật toán tìm kiếm tuần tự, Binary Search sở hữu độ phức tạp chỉ là O(log n) cực kỳ ấn tượng. Với mảng 1 tỷ phần tử, bạn chỉ cần tối đa khoảng 30 lần so sánh để tìm ra kết quả chính xác nhất.
Triển khai mã nguồn C++17 chuyên nghiệp
Mã nguồn dưới đây minh họa cách cài đặt Binary Search dạng vòng lặp để tối ưu bộ nhớ Stack so với đệ quy. Để chuẩn bị mảng dữ liệu đầu vào chuẩn xác, bạn có thể áp dụng các thuật toán sắp xếp trong C++ như std::sort trước khi gọi hàm tìm kiếm.
#include #include #include / Thuật toán Tìm kiếm nhị phân tối ưu Phiên bản: C++17 Độ phức tạp: O(log n) / int binarySearch(const std::vector& arr, int target) { int left = 0; int right = static_cast(arr.size()) - 1; while (left <= right) { // Tránh lỗi tràn số (overflow) thay vì dùng (left + right) / 2 int mid = left + (right - left) / 2; if (arr[mid] == target) { return mid; // Tìm thấy mục tiêu } if (arr[mid] < target) { left = mid + 1; // Tìm ở nửa bên phải } else { right = mid - 1; // Tìm ở nửa bên trái } } return -1; // Không tìm thấy } int main() { std::vector data = {10, 14, 19, 26, 27, 31, 33, 35, 42, 44}; int target = 31; int result = binarySearch(data, target); if (result != -1) { std::cout << "Phan tu tai index: " << result << std::endl; } else { std::cout << "Khong tim thay phan tu!" << std::endl; } return 0; }Interpolation Search và sự cải tiến của các thuật toán tìm kiếm
Kiỹ thuật Interpolation Search hay tìm kiếm nội suy là một biến thể nâng cao nhằm cải thiện tốc độ của nhị phân. Thuật toán này hoạt động dựa trên logic tương tự cách chúng ta tìm kiếm một từ trong cuốn từ điển giấy. Nó dựa vào sự phân bổ dữ liệu để dự đoán vị trí có khả năng chứa mục tiêu cao nhất hiện tại.
Phương pháp này có tính chất đặc thù hơn các thuật toán tìm kiếm khác nhờ công thức nội suy tuyến tính thông minh. Khi dữ liệu được phân bổ đồng đều, nó có thể đạt tới độ phức tạp thời gian trung bình là O(log(log n)). Đây là một con số tiệm cận với tốc độ truy cập tức thời trong các cấu trúc phức tạp nhất.
Công thức dự đoán vị trí (Position Probing)
Thay vì luôn chọn vị trí ở chính giữa, Interpolation Search tính toán pos dựa trên giá trị của các biên mảng. Công thức toán học cốt lõi để xác định vị trí thăm dò (probing) được mô tả chi tiết như sau:
pos = low + [ (target - arr[low]) (high - low) / (arr[high] - arr[low]) ]
Trong đó, low và high lần lượt là chỉ mục thấp nhất và cao nhất của phạm vi đang tìm kiếm. Nếu giá trị mục tiêu gần với phần tử ở biên cao, thuật toán sẽ nhảy tới các vị trí gần cuối mảng. Ngược lại, nếu mục tiêu nhỏ, nó sẽ ưu tiên kiểm tra các vị trí nằm ở phía đầu danh sách mảng.
Triển khai Java 17 cho tìm kiếm nội suy
Dưới đây là phiên bản cài đặt thực tế bằng Java, chú trọng vào việc kiểm tra điều kiện biên để tránh lỗi.
public class InterpolationSearch { / Thuật toán Tìm kiếm nội suy @param arr Mảng đã sắp xếp và có phân bổ đều @param target Giá trị cần tìm @return Index của phần tử hoặc -1 / public static int interpolationSearch(int[] arr, int target) { int low = 0, high = arr.length - 1; // Đảm bảo mục tiêu nằm trong dải giá trị của mảng while (low = arr[low] && target <= arr[high]) { if (low == high) { if (arr[low] == target) return low; return -1; } // Công thức nội suy dự đoán vị trí int pos = low + (int)((double)(high - low) / (arr[high] - arr[low]) (target - arr[low])); if (arr[pos] == target) { return pos; } if (arr[pos] < target) { low = pos + 1; } else { high = pos - 1; } } return -1; } public static void main(String[] args) { int[] sortedData = {10, 12, 13, 16, 18, 19, 20, 21, 22, 23, 24, 33, 35, 42, 47}; int key = 18; int index = interpolationSearch(sortedData, key); System.out.println("Tim thay tai vi tri: " + index); } }So sánh hiệu năng giữa các thuật toán tìm kiếm
Việc lựa chọn sai công cụ trong bộ sưu tập các thuật toán tìm kiếm có thể dẫn tới nghẽn cổ chai hệ thống. Bảng dưới đây tóm tắt các thông số quan trọng để lập trình viên dễ dàng đưa ra quyết định tối ưu nhất. Chúng ta cần cân nhắc kỹ giữa độ phức tạp thời gian và yêu cầu về trạng thái dữ liệu trước khi code.
| Thuật toán | Độ phức tạp (Best) | Độ phức tạp (Average) | Yêu cầu dữ liệu | Ứng dụng tiêu biểu |
|---|---|---|---|---|
| Linear Search | O(1) | O(n) | Không yêu cầu | Mảng nhỏ, chưa sắp xếp |
| Binary Search | O(1) | O(log n) | Phải sắp xếp | Tìm kiếm trong danh bạ, từ điển |
| Interpolation | O(1) | O(log(log n)) | Sắp xếp & Phân bổ đều | Hệ thống phân phối số liệu lớn |
Trong thực tế, Binary Search là lựa chọn an toàn nhất vì nó ổn định ngay cả khi dữ liệu phân bổ không đều. Interpolation Search dù nhanh hơn trên lý thuyết nhưng rất dễ rơi vào trường hợp xấu nhất O(n) nếu dữ liệu bị lệch. Bạn nên kiểm tra kỹ đặc tính của tập dữ liệu đầu vào trước khi quyết định sử dụng nội suy tuyến tính.
Những sai lầm thường gặp khi lập trình tìm kiếm
Nhiều lập trình viên kinh nghiệm vẫn thường mắc các lỗi logic tinh vi khi triển khai các thuật toán tìm kiếm trong dự án. Một trong những lỗi phổ biến nhất là tràn số nguyên khi tính toán chỉ số trung tâm trong Binary Search truyền thống. Việc sử dụng (low + high) / 2 có thể gây ra lỗi nghiêm trọng khi tổng của hai biên vượt giới hạn kiểu dữ liệu.
Sai lầm tiếp theo nằm ở việc quên kiểm tra tính toàn vẹn của dữ liệu đã sắp xếp trước khi tìm kiếm. Việc thực hiện Binary Search trên một mảng chưa sắp xếp sẽ chỉ trả về những kết quả sai lệch và không thể dự đoán. Luôn đảm bảo dữ liệu đầu vào tuân thủ các điều kiện tiên quyết của giải thuật để tránh những bug khó debug.
Cuối cùng, việc lạm dụng quá mức việc sao chép mảng trong mỗi bước tìm kiếm đệ quy sẽ tiêu tốn bộ nhớ vô ích. Bạn nên ưu tiên sử dụng các biến tham chiếu và chỉ số biên để làm việc trực tiếp trên mảng gốc đang hiện có. Điều này giúp tối ưu hóa không gian lưu trữ và tăng tốc độ xử lý tổng thể của chương trình máy tính.
Ứng dụng thực tế của các thuật toán tìm kiếm
Trong các hệ thống cơ sở dữ liệu hiện đại, các thuật toán tìm kiếm chính là “trái tim” của các bộ máy đánh chỉ mục. Công nghệ B-Tree hay Indexing thực chất là các biến thể mở rộng dựa trên nguyên lý của cây tìm kiếm nhị phân thông minh. Khi bạn gõ một từ khóa trên công cụ tìm kiếm, hàng loạt thuật toán được thực thi ngầm để trả về kết quả.
Hơn nữa, trong lĩnh vực xử lý đồ họa và trí tuệ nhân tạo, tìm kiếm cũng đóng vai trò kiến tạo không gian trạng thái. Kỹ thuật Binary Search được ứng dụng để tối ưu hóa quá trình dò tia hoặc xác định ranh giới va chạm vật lý. Hiểu sâu về các giải thuật này sẽ giúp kiến trúc sư phần mềm xây dựng được những hệ thống có khả năng mở rộng.
Tóm lại, việc nghiên cứu cẩn thận các thuật toán tìm kiếm là một bước đi chiến lược trong hành trình phát triển nghề nghiệp. Hãy bắt đầu từ những khái niệm đơn giản nhất như Linear Search trước khi tiến tới các kỹ thuật tìm kiếm đỉnh cao. Với kiến thức vững chắc, bạn hoàn toàn có thể tối ưu hóa bất kỳ hệ thống dữ liệu phức tạp nào trong tương lai.
Hy vọng bài viết này đã cung cấp cho bạn cái nhìn chuyên sâu và thực tế nhất về các thuật toán tìm kiếm hiện đại. Hãy tiếp tục thực hành triển khai mã nguồn thường xuyên để làm chủ hoàn toàn các kỹ thuật quan trọng này trong lập trình.
Cập nhật lần cuối 04/03/2026 by Hiếu IT