Trong thế giới phần mềm, việc nắm vững cấu trúc dữ liệu và giải thuật không chỉ là yêu cầu tuyển dụng mà còn là thước đo tư duy của một kỹ sư. Hiểu rõ cách dữ liệu vận hành giúp bạn viết mã nguồn tối ưu, dễ bảo trì và có khả năng mở rộng vượt trội. Bài viết này phân tích chuyên sâu từ nguyên lý đến thực thi, giúp bạn làm chủ nền mòn quan trọng nhất trong lộ trình phát triển định hướng Senior.
Bản chất của cấu trúc dữ liệu và giải thuật trong phần mềm
Về cốt lõi, chương trình máy tính là sự kết hợp giữa lưu trữ thông tin và các chỉ thị thao tác trên thông tin đó. Cấu trúc dữ liệu đóng vai trò là “vật chứa”, xác định cách dữ liệu được tổ chức trong bộ nhớ (RAM), trong khi giải thuật là “công thức” xử lý để đạt được kết quả mong muốn. Một kỹ sư giỏi không bao giờ chọn cấu trúc dữ liệu một cách ngẫu nhiên; họ chọn dựa trên sự đánh đổi (trade-off) giữa tốc độ xử lý và dung lượng bộ nhớ sử dụng.
Hình 1: Sơ đồ mô phỏng cấu trúc dữ liệu dạng cây (Tree) trong tổ chức thư mục hệ thống.
Giải thuật cần tuân thủ các đặc trưng nghiêm ngặt: tính xác định (mọi bước phải rõ ràng), tính hữu hạn (phải dừng sau một số bước nhất định) và hiệu quả. Trong môi trường doanh nghiệp, tư duy lập trình sắc bén thể hiện ở việc bạn biết khi nào nên dùng một mảng tĩnh để ưu tiên tốc độ truy cập, hoặc khi nào cần một danh sách liên kết để tối ưu hóa việc chèn ép dữ liệu liên tục.
Hình 2: Trình tự các bước thực hiện của một giải thuật giải quyết bài toán thực tế.
Phân tích độ phức tạp thuật toán (Big O Notation)
Để đánh giá một giải thuật, chúng ta sử dụng độ phức tạp thuật toán (Big O Notation). Đây là ngôn ngữ chung để đo lường sự tăng trưởng của thời gian thực thi hoặc không gian bộ nhớ khi kích thước đầu vào (n) tăng lên. Một giải thuật có độ phức tạp $O(1)$ là lý tưởng nhất, trong khi $O(2^n)$ hoặc $O(n!)$ thường được coi là không khả thi cho các tập dữ liệu lớn.
Kinh nghiệm thực chiến cho thấy, việc tối ưu từ $O(n^2)$ xuống $O(n log n)$ có thể biến một tác vụ chạy mất vài tiếng đồng hồ thành vài giây. Tuy nhiên, lập trình viên cần tỉnh táo: đôi khi giải thuật có độ phức tạp lý thuyết tốt hơn nhưng lại chạy chậm hơn trên tập dữ liệu nhỏ do chi phí hằng số (constant overhead) lớn. Luôn luôn thực hiện benchmark trên dữ liệu thực tế trước khi quyết định thay đổi cấu trúc cốt lõi.
Phân loại cấu trúc dữ liệu và chiến lược lưu trữ
Cấu trúc dữ liệu được chia thành hai nhánh chính dựa trên cách sắp xếp các phần tử trong bộ nhớ vật lý và logic: tuyến tính và phi tuyến tính. Hiểu rõ sự khác biệt này giúp bạn định hình cấu trúc mã nguồn một cách khoa học.
 Phân loại cấu trúc dữ liệuHình 3: Bản đồ phân loại các hệ thống cấu trúc dữ liệu phổ biến trong khoa học máy tính.
Phân loại cấu trúc dữ liệuHình 3: Bản đồ phân loại các hệ thống cấu trúc dữ liệu phổ biến trong khoa học máy tính.
Cấu trúc dữ liệu tuyến tính
Các phần tử được sắp xếp nối tiếp nhau, tạo thuận lợi cho việc duyệt tuần tự. Mặc dù đơn giản, nhưng mỗi loại lại có đặc tính truy cập bộ nhớ khác nhau:
- Mảng (Array): Các phần tử nằm kề nhau trong bộ nhớ. Ưu điểm là truy cập hằng số $O(1)$ qua chỉ số, nhưng chèn/xóa ở giữa mảng rất tốn kém ($O(n)$) do phải dịch chuyển các phần tử còn lại.
- Danh sách liên kết (Linked List): Các phần tử (Node) nằm rải rác, kết nối qua con trỏ. Nó cực kỳ linh hoạt cho việc thêm/xóa nhưng lại tốn thêm bộ nhớ cho con trỏ và không hỗ trợ truy cập ngẫu nhiên.
- Ngăn xếp (Stack – LIFO): Hoạt động như chồng đĩa, dùng trong các bài toán đệ quy hoặc quản lý vùng nhớ (Call Stack).
- Hàng đợi (Queue – FIFO): Giống như xếp hàng mua vé, quan trọng trong các hệ thống tin nhắn (Message Queue) và lập lịch tiến trình.
Cấu trúc dữ liệu phi tuyến tính
Khi mối quan hệ giữa các thành phần trở nên phức tạp và mang tính phân cấp, cấu trúc phi tuyến tính là lựa chọn bắt buộc. Cây (Tree) cho phép tìm kiếm dữ liệu có thứ tự cực nhanh, trong khi Đồ thị (Graph) là xương sống của các mạng xã hội (liên kết bạn bè) và hệ thống dẫn đường (Google Maps). Khi làm việc với các khối dữ liệu lớn lên đến hàng triệu bản ghi, việc chọn đúng cấu trúc cây cân bằng (như AVL hay Red-Black Tree) sẽ quyết định sự sống còn của ứng dụng.
Các giải thuật tìm kiếm và sắp xếp tối ưu
Trong cấu trúc dữ liệu và giải thuật, tìm kiếm và sắp xếp là hai mảng có ứng dụng thực tế cao nhất. Mọi hệ thống quản trị cơ sở dữ liệu (DBMS) đều dựa trên các giải thuật này để trả về kết quả cho người dùng.
Giải thuật Tìm kiếm Nhị phân (Binary Search)
Tìm kiếm nhị phân chỉ hoạt động trên mảng đã sắp xếp nhưng mang lại hiệu suất kinh ngạc $O(log n)$. Ví dụ, với 1 tỷ phần tử, tìm kiếm tuần tự cần tối đa 1 tỷ lần so sánh, nhưng tìm kiếm nhị phân chỉ cần tối đa 30 lần.
Hình 4: Cơ chế chia để trị giúp thu hẹp không gian tìm kiếm nhị phân theo lũy thừa cơ số 2.
Dưới đây là mã nguồn thực thi chuẩn với Python 3.12, bao gồm kiểm soát lỗi và gợi ý kiểu (Type Hinting):
from typing import List, Optional
def binary_search(arr: List[int], target: int) -> Optional[int]:
"""
Thực hiện tìm kiếm nhị phân trên mảng đã sắp xếp.
Độ phức tạp thời gian: O(log n)
Độ phức tạp không gian: O(1)
"""
low, high = 0, len(arr) - 1
try:
while low <= high:
mid = (low + high) // 2
guess = arr[mid]
if guess == target:
return mid
if guess > target:
high = mid - 1
else:
low = mid + 1
return None
except TypeError:
print("Lỗi: Mảng đầu vào phải chứa các số nguyên.")
return None
# Chạy thử nghiệm
data = [1, 3, 5, 7, 9, 11, 15, 20]
target_val = 7
result = binary_search(data, target_val)
if result is not None:
print(f"Phần tử {target_val} nằm tại vị trí index: {result}") # Output: 3
else:
print("Không tìm thấy phần tử.")So sánh các giải thuật sắp xếp
Sắp xếp nổi bọt (Bubble Sort) thường chỉ dùng để giảng dạy vì hiệu suất kém ($O(n^2)$). Trong các dự án thực tế, Quick Sort và Merge Sort là hai “trụ cột” nhờ độ phức tạp trung bình $O(n log n)$. Merge Sort có tính ổn định (stable) nhưng tốn thêm bộ nhớ, trong khi Quick Sort có tốc độ thực thi tại chỗ (in-place) nhanh hơn nhưng có thể rơi vào trường hợp xấu nhất nếu không chọn phần tử chốt (pivot) tốt.
Hình 5: Minh họa cách Quick Sort phân đoạn dữ liệu dựa trên giá trị Pivot.
Sức mạnh của Đệ quy và Quy hoạch động
Đệ quy là kỹ thuật hàm tự gọi lại chính nó, lý tưởng để duyệt qua các cấu trúc có tính lặp lại như Cây hoặc Đồ thị. Tuy nhiên, đệ quy thuần túy thường dẫn đến việc tính toán lặp lại nhiều lần. Đây chính là lúc Quy hoạch động (Dynamic Programming) tỏa sáng.
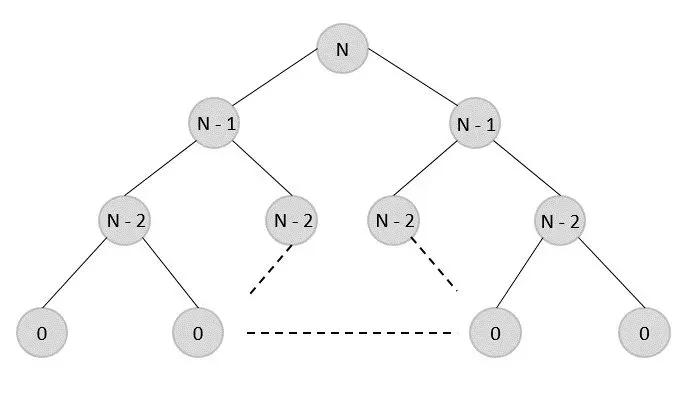 Quy hoạch độngHình 6: Phương pháp lưu trữ kết quả trung gian để tối ưu hóa hiệu suất của quy hoạch động.
Quy hoạch độngHình 6: Phương pháp lưu trữ kết quả trung gian để tối ưu hóa hiệu suất của quy hoạch động.
Quy hoạch động giải quyết bài toán lớn bằng cách chia nhỏ thành các bài toán con và tối ưu hiệu suất bằng cách lưu trữ kết quả (Memoization) của các bài toán con đó. Một ví dụ điển hình là tính dãy Fibonacci hoặc bài toán Cái túi (Knapsack Problem). Thay vì độ phức tạp lũy thừa, quy hoạch động đưa về độ phức tạp tuyến tính hoặc đa thức, giúp tiết kiệm tài nguyên hệ thống đáng kể.
Kinh nghiệm thực chiến và sai lầm thường gặp
Với hơn một thập kỷ phát triển phần mềm, tôi nhận thấy lỗi phổ biến nhất của các lập trình viên trẻ là “tối ưu hóa sớm” (premature optimization). Họ cố gắng áp dụng những giải thuật phức tạp cho các tập dữ liệu nhỏ, dẫn đến mã nguồn khó đọc và tốn thời gian không cần thiết.
Một khía cạnh khác ít được nhắc đến là Cache Locality. Mảng (Array) thường chạy nhanh hơn Danh sách liên kết (Linked List) trên CPU hiện đại không chỉ vì độ phức tạp $O(1)$ mà vì dữ liệu của mảng nằm liên tục, giúp tận dụng tối đa cơ chế nạp trước của bộ nhớ đệm (L1/L2 Cache). Khi thiết kế cấu trúc dữ liệu và giải thuật cho hệ thống xử lý thời gian thực, hiểu biết về phần cứng là điều kiện cần để trở thành kỹ sư cấp cao.
Cuối cùng, hãy luôn kiểm tra các trường hợp biên (edge cases). Một hàm tìm kiếm nhị phân có thể gây tràn số (integer overflow) nếu tính mid = (low + high) // 2 với các mảng cực lớn trong ngôn ngữ như Java hay C++. Cách an toàn hơn là mid = low + (high - low) // 2. Những chi tiết nhỏ này phân biệt một lập trình viên trung bình và một chuyên gia thực thụ.
Làm chủ kiến thức về cấu trúc dữ liệu và giải thuật là hành trình rèn luyện bền bỉ. Hãy bắt đầu từ việc hiểu sâu nguyên lý của từng cấu trúc, thực hành triển khai mã nguồn thủ công thay vì phụ thuộc hoàn toàn vào thư viện có sẵn để cảm nhận được luồng dữ liệu di chuyển trong bộ nhớ máy tính. Bước tiếp theo, bạn có thể thử thách bản thân với các bài toán đồ thị và tối ưu hóa tổ hợp để nâng tầm tư duy giải quyết vấn đề.
Cập nhật lần cuối 01/03/2026 by Hiếu IT