Việc triển khai code python trên visual studio code đã trở thành tiêu chuẩn công nghiệp nhờ vào sự linh hoạt của hệ sinh thái extension và khả năng tích hợp sâu với Jupyter Notebooks. Trong bài viết này, chúng ta sẽ không chỉ dừng lại ở việc chạy code cơ bản mà sẽ đi sâu vào quy trình xây dựng một dự án khoa học dữ liệu hoàn chỉnh, từ thiết lập môi trường đến huấn luyện mạng thần kinh nhân tạo.
Thiết lập môi trường Anaconda và Workspace chuyên nghiệp
Để thực hiện code python trên visual studio code một cách ổn định, việc quản lý phụ thuộc (dependency management) là yếu tố tiên quyết. Thay vì sử dụng môi trường Global, chúng ta sẽ sử dụng môi trường anaconda để cách ly các thư viện, tránh xung đột phiên bản.
Đầu tiên, bạn cần khởi tạo một môi trường Python 3.10 ổn định cho các bài toán Data Science. Mở terminal (CMD hoặc PowerShell) và thực hiện lệnh sau:
# Tạo môi trường mới với các thư viện lõi
conda create -n ds_vision python=3.10 pandas jupyter seaborn scikit-learn keras tensorflow -y
# Kích hoạt môi trường vừa tạo
conda activate ds_visionKỹ năng chuyên gia: Khi làm việc trên dự án thực tế, hãy luôn tạo file environment.yml để đồng bộ môi trường giữa các thành viên trong team. Trong VS Code, sau khi mở folder dự án (ví dụ titanic_analysis), bạn nhấn Ctrl+Shift+P, gõ “Python: Select Interpreter” và chọn đúng môi trường ds_vision. Điều này đảm bảo tính năng IntelliSense và Pylance hoạt động chính xác nhất khi bạn viết code python trên visual studio code.
 Creating a new Jupyter Notebook
Creating a new Jupyter Notebook
Tiếp theo, hãy tạo một file Jupyter Notebook mới (Analysis.ipynb). VS Code cung cấp giao diện native cho Notebook, cho phép bạn chạy từng block code cực kỳ trực quan. Đừng quên chọn Kernel ở góc trên bên phải màn hình để trỏ đúng về môi trường Anaconda đã thiết lập.
 Selecting a Jupyter Notebook Kernel
Selecting a Jupyter Notebook Kernel
Tiền xử lý dữ liệu với thư viện Pandas và Numpy
Bước quan trọng nhất trong mọi dự án AI là tiền xử lý dữ liệu. Dữ liệu thô (raw data) thường chứa nhiễu, lỗi định dạng hoặc giá trị thiếu (missing values). Chúng ta sẽ sử dụng Titanic dataset để minh họa quy trình này khi thực hiện code python trên visual studio code.
Trước tiên, hãy load dữ liệu và quan sát cấu trúc bằng thư viện pandas:
import pandas as pd
import numpy as np
# Đọc dữ liệu từ file CSV
# Độ phức tạp thời gian: O(n) với n là số hàng trong dataset
try:
data = pd.read_csv('titanic3.csv')
print(f"Dataset loaded: {data.shape[0]} rows, {data.shape[1]} columns")
except FileNotFoundError:
print("Lỗi: Không tìm thấy file titanic3.csv. Hãy kiểm tra đường dẫn!")
# Thay thế các ký tự '?' (thiếu dữ liệu) bằng NaN để xử lý chuẩn hóa
data.replace('?', np.nan, inplace=True)
# Ép kiểu dữ liệu về dạng float cho các cột số học
# Điều này cực kỳ quan trọng để tránh lỗi khi tính toán ma trận sau này
data = data.astype({"age": np.float64, "fare": np.float64})Kinh nghiệm thực tế: Một lỗi phổ biến khi viết code python trên visual studio code là không kiểm tra kiểu dữ liệu sau khi load. Sử dụng data.info() thường xuyên giúp bạn phát hiện các cột dạng object vốn dĩ phải là numeric, từ đó tránh được các lỗi TypeError khi đưa vào mô hình.
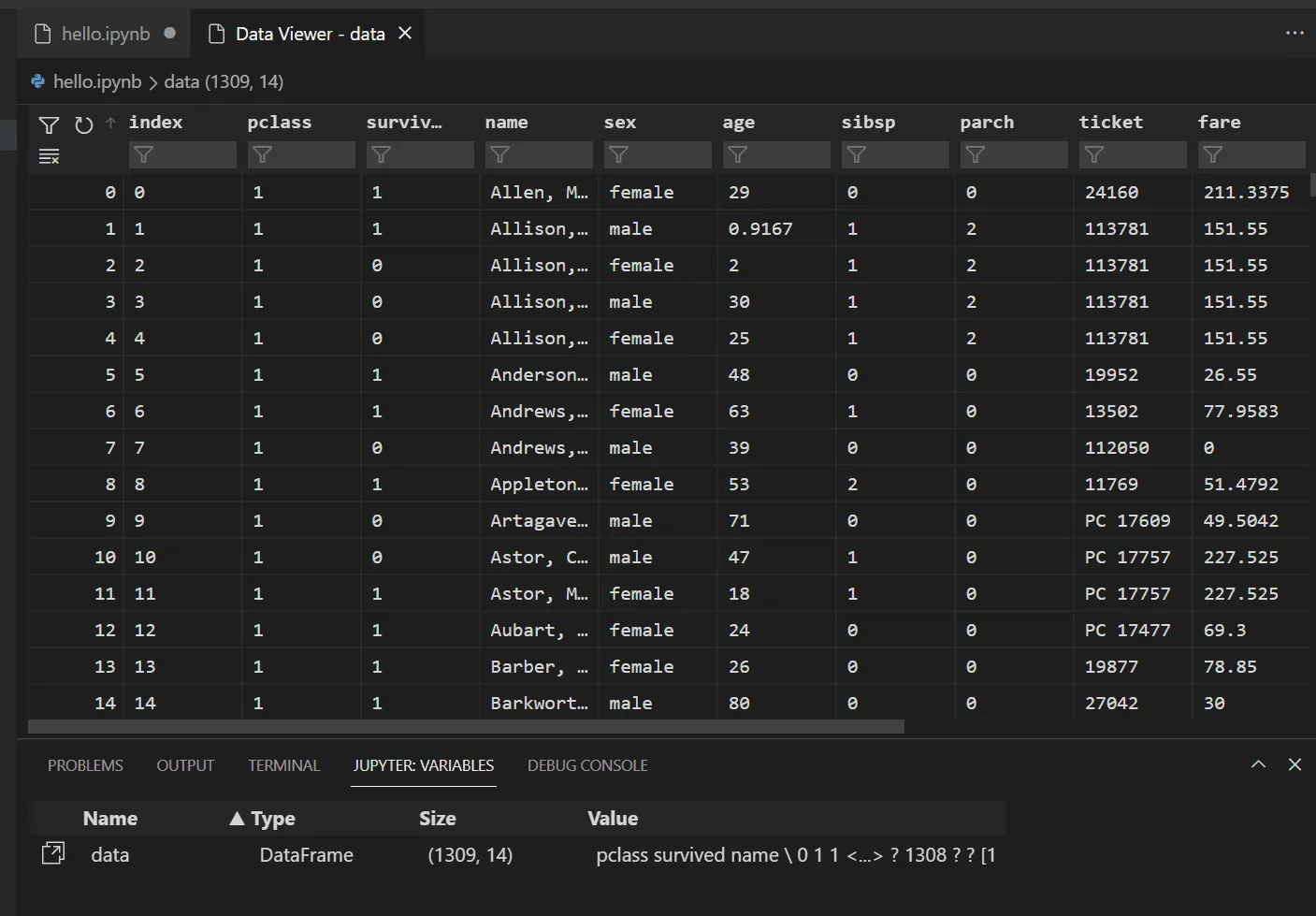 Data viewer and variable explorer
Data viewer and variable explorer
Phân tích tương quan và trích xuất đặc trưng (Feature Engineering)
Sau khi dọn dẹp, chúng ta cần xác định những yếu tố nào ảnh hưởng mạnh nhất đến khả năng sống sót. Một mẹo nhỏ cho người mới là sử dụng biểu đồ Violin để quan sát phân phối dữ liệu.
import seaborn as sns
import matplotlib.pyplot as plt
# Trực quan hóa mối quan hệ giữa các biến
fig, axs = plt.subplots(ncols=5, figsize=(30, 5))
sns.violinplot(x="survived", y="age", hue="sex", data=data, ax=axs[0])
sns.pointplot(x="pclass", y="survived", hue="sex", data=data, ax=axs[3])
plt.show()Dựa trên biểu đồ, ta thấy rằng giới tính (sex) và hạng vé (pclass) có tác động cực lớn đến xác suất sống sót. Để máy tính hiểu được, ta cần chuyển các biến phân loại (categorical) sang dạng số:
# Chuyển đổi Sex: male -> 1, female -> 0
data.replace({'male': 1, 'female': 0}, inplace=True)
# Tạo đặc trưng mới: 'relatives' (tổng số người thân đi cùng)
# Logic: Nếu sibsp + parch > 0 thì hành khách có người thân
data['relatives'] = data.apply(lambda row: int((row['sibsp'] + row['parch']) > 0), axis=1)
# Lọc bỏ các thuộc tính không cần thiết để giảm dimensionality (tránh overfitting)
data = data[['sex', 'pclass', 'age', 'relatives', 'fare', 'survived']].dropna()Khi thực hiện các thao tác này trong quá trình code python trên visual studio code, bạn có thể sử dụng “Data Viewer” tích hợp sẵn để xem trực tiếp bảng dữ liệu như trong Excel, giúp phát hiện nhanh các sai sót logic.
Xây dựng mô hình phân loại với thuật toán Naive Bayes
Chúng ta sẽ bắt đầu với thuật toán Naive Bayes, một trong số các thuật toán phân loại dựa trên xác suất có độ phức tạp tính toán thấp nhưng hiệu quả cao cho dữ liệu dạng bảng. Đây là bước đệm lý tưởng khi bạn bắt đầu viết code python trên visual studio code cho Machine Learning.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.naive_bayes import GaussianNB
from sklearn import metrics
# 1. Chia tập dữ liệu: 80% để huấn luyện, 20% để kiểm thử (validation)
x_train, x_test, y_train, y_test = train_test_split(
data[['sex','pclass','age','relatives','fare']],
data.survived,
test_size=0.2,
random_state=0
)
# 2. Chuẩn hóa dữ liệu (Feature Scaling)
# Chuyển dữ liệu về phân phối chuẩn (mean=0, std=1)
# Cực kỳ quan trọng cho các thuật toán dựa trên khoảng cách hoặc xác suất
sc = StandardScaler()
X_train = sc.fit_transform(x_train)
X_test = sc.transform(x_test)
# 3. Khởi tạo và huấn luyện mô hình
model = GaussianNB()
model.fit(X_train, y_train)
# 4. Đánh giá độ chính xác accuracy
predict_test = model.predict(X_test)
print(f"Naive Bayes Accuracy: {metrics.accuracy_score(y_test, predict_test):.2%}")Phân tích Complexity: Thuật toán Naive Bayes có độ phức tạp huấn luyện là O(np) (với n là số mẫu và p là số đặc trưng), khiến nó chạy cực nhanh ngay cả trên laptop cấu hình yếu khi bạn code python trên visual studio code. Tuy nhiên, điểm yếu của nó là giả định các đặc trưng độc lập với nhau — một điều hiếm khi xảy ra hoàn toàn trong thực tế.
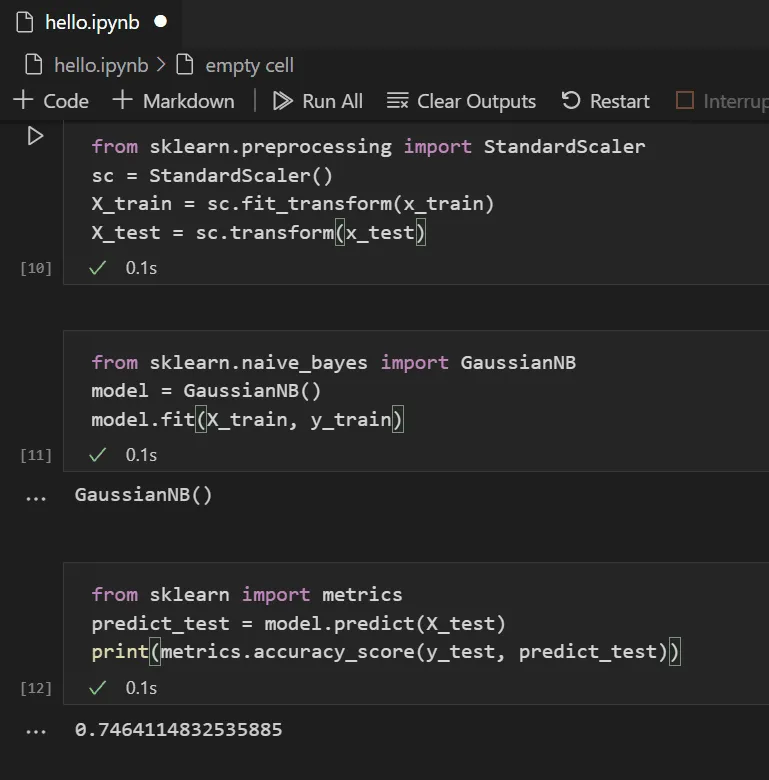 Running the trained model against test data
Running the trained model against test data
Phát triển mạng thần kinh nhân tạo với Keras và TensorFlow
Khi bài toán trở nên phức tạp hơn, một mô hình machine learning truyền thống có thể không bắt kịp các mối quan hệ phi tuyến. Đây là lúc chúng ta cần ứng dụng mạng thần kinh nhân tạo (Artificial Neural Network – ANN).
Sử dụng thư viện Keras tích hợp trong TensorFlow, chúng ta sẽ xây dựng một cấu trúc Sequential gồm 3 lớp layer xếp chồng lên nhau. Đây là một ví dụ điển hình về hướng tiếp cận Deep Learning khi triển khai code python trên visual studio code.
from keras.models import Sequential
from keras.layers import Dense
# Khởi tạo mô hình tuần tự
model_nn = Sequential()
# Thêm lớp ẩn đầu tiên: 5 neuron, hàm kích hoạt ReLU
# input_dim=5 tương ứng với 5 đặc trưng đầu vào
model_nn.add(Dense(5, kernel_initializer='uniform', activation='relu', input_dim=5))
# Thêm lớp ẩn thứ hai
model_nn.add(Dense(5, kernel_initializer='uniform', activation='relu'))
# Lớp đầu ra: 1 neuron, hàm kích hoạt Sigmoid (cho xác suất 0-1)
model_nn.add(Dense(1, kernel_initializer='uniform', activation='sigmoid'))
# Compile mô hình với optimizer 'adam' (Adaptive Moment Estimation)
model_nn.compile(optimizer="adam", loss='binary_crossentropy', metrics=['accuracy'])
# Huấn luyện với 50 vòng lặp (epochs)
model_nn.fit(X_train, y_train, batch_size=32, epochs=50, verbose=0)
# Kiểm tra hiệu năng trên tập test
y_pred = np.rint(model_nn.predict(X_test).flatten())
print(f"Neural Network Accuracy: {metrics.accuracy_score(y_test, y_pred):.2%}")Tại sao dùng Sigmoid ở lớp cuối? Vì chúng ta đang giải quyết bài toán phân loại nhị phân (Binary Classification). Nhờ hàm Sigmoid, kết quả đầu ra sẽ nằm trong khoảng [0, 1], đại diện cho xác suất một hành khách sống sót. Khi thực hiện code python trên visual studio code, bạn sẽ thấy ANN thường cho độ chính xác cao hơn Naive Bayes khoảng 4-5% trên cùng một bộ dữ liệu.
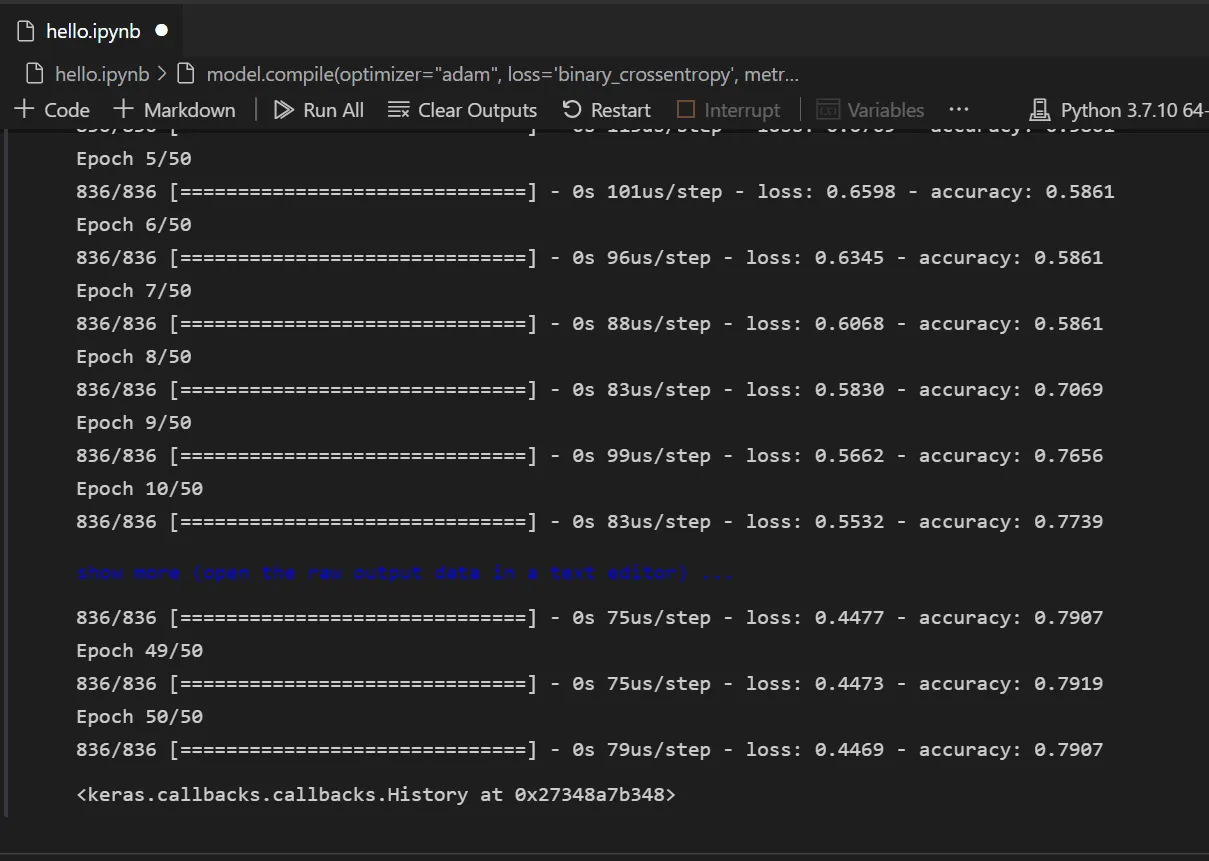 Build and train the neural network
Build and train the neural network
Các lỗi thường gặp khi coding và cách khắc phục
Trong quá trình hướng dẫn lập trình code python trên visual studio code, tôi nhận thấy 3 lỗi “kinh điển” mà các developer hay mắc phải:
- Chưa kích hoạt đúng Environment: Bạn cài thư viện vào Anaconda nhưng file Notebook lại chạy bằng Python Global.
- Giải pháp: Luôn kiểm tra tên môi trường ở thanh trạng thái dưới cùng của VS Code.
- Lỗi bộ nhớ (Out of Memory): Khi xử lý dataset lớn hoặc training deep learning với
batch_sizequá cao.- Tip: Hãy bắt đầu với
batch_size=32và tăng dần nếu bộ nhớ GPU/RAM cho phép.
- Tip: Hãy bắt đầu với
- Data Leakage (Rò rỉ dữ liệu): Bạn thực hiện
fit_transformtrên cả tập test.- Nguyên tắc: Chỉ
fittrên tập train, sau đó dùng scaler đó đểtransformtập test. Nếu làm sai, độ chính xác accuracy sẽ cao ảo nhưng fail khi đưa vào thực tế.
- Nguyên tắc: Chỉ
Để tối ưu hóa trải nghiệm code python trên visual studio code, hãy tận dụng tính năng Variables Explorer. Tính năng này cho phép bạn soi vào từng biến array, dataframe mà không cần phải print() thủ công, giúp tiết kiệm hàng giờ debug.
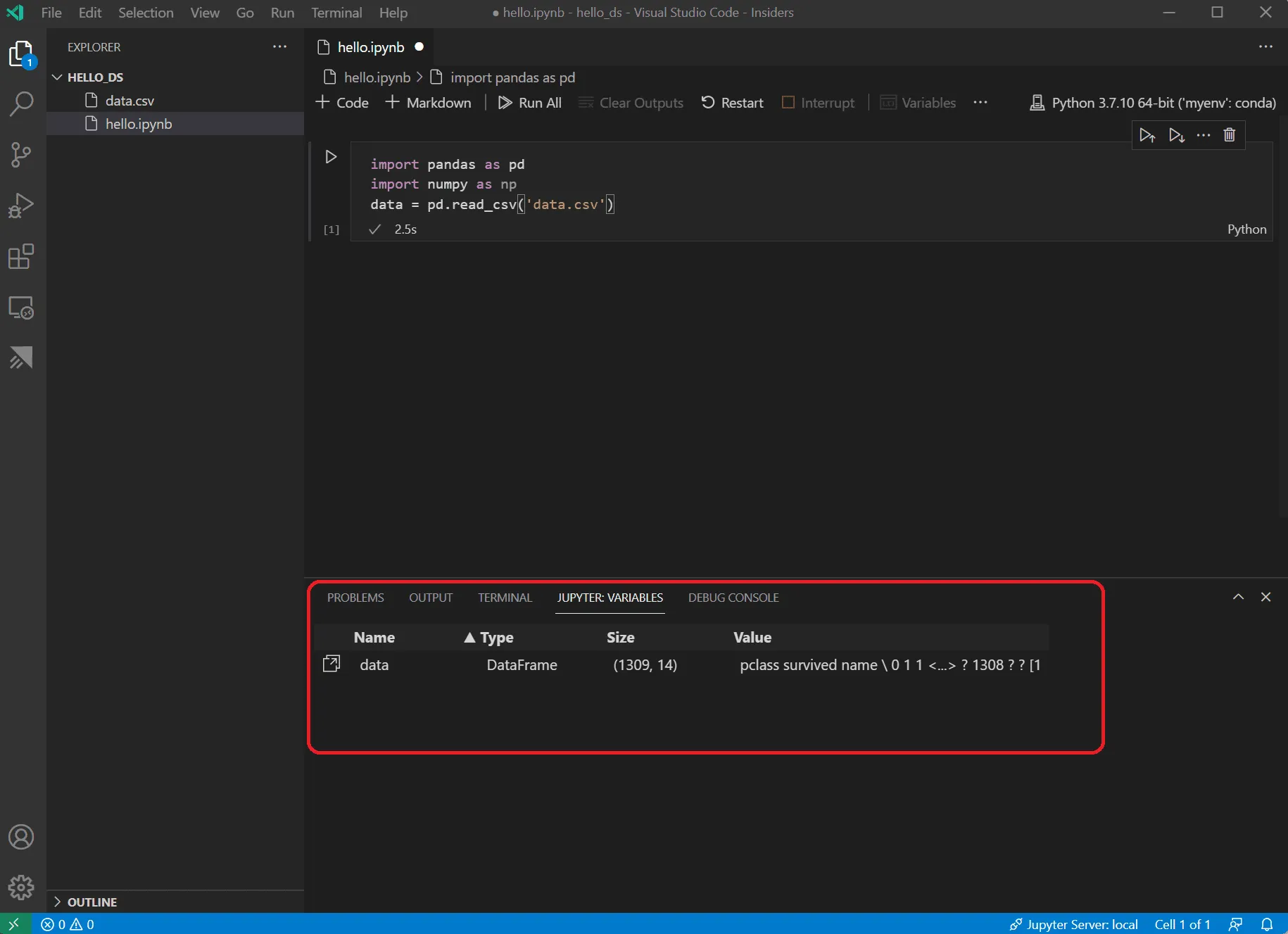 Variables pane
Variables pane
Ứng dụng thực tế của quy trình lập trình này
Mẫu code python trên visual studio code mà chúng ta vừa xây dựng không chỉ áp dụng cho thảm họa Titanic. Trong thực tế, cấu trúc tiền xử lý dữ liệu -> trích xuất đặc trưng -> huấn luyện mô hình được dùng rộng rãi trong:
- Ngân hàng: Dự đoán nợ xấu và rủi ro tín dụng.
- Thương mại điện tử: Gợi ý sản phẩm dựa trên hành vi người dùng (Recommendation System).
- Y tế: Phân loại tế bào ung thư dựa trên các chỉ số sinh hóa.
Việc làm chủ công cụ trình soạn thảo code Visual Studio Code kết hợp với Python sẽ mở ra cơ hội trong các lĩnh vực AI và Big Data đầy tiềm năng.
Việc thuần thục cách viết code python trên visual studio code là bước khởi đầu quan trọng để trở thành kỹ sư AI chuyên nghiệp. Hãy thử thay đổi cấu trúc các lớp neuron hoặc sử dụng các bộ dữ liệu khác trên Kaggle để nâng cao kỹ năng xử lý dữ liệu thực tế của bạn ngay hôm nay.
Cập nhật lần cuối 02/03/2026 by Hiếu IT