Trong hệ sinh thái khoa học dữ liệu, thư viện pandas trong python đóng vai trò là cột trụ quan trọng nhất cho việc cấu trúc và thao tác dữ liệu bảng. Bằng cách kế thừa hiệu năng từ Numpy và tính linh hoạt của lập trình hướng đối tượng, thư viện này cho phép các kỹ sư xử lý hàng triệu bản ghi chỉ với vài dòng mã lệnh tối ưu.
Bản chất kiến trúc và sức mạnh của Pandas
Trước khi bắt đầu viết mã, một lập trình viên senior cần hiểu rằng thư viện pandas trong python không đơn thuần là một công cụ đọc file CSV. Nó được xây dựng dựa trên triết lý “Vectorization”, tức là thực hiện các phép toán trên toàn bộ mảng thay vì sử dụng vòng lặp for truyền thống của Python. Điều này giúp tốc độ xử lý nhanh hơn hàng chục lần nhờ vào việc gọi trực tiếp các hàm C-API bên dưới.
Hai cấu trúc dữ liệu cốt lõi mà bạn phải nắm vững là Series (mảng 1 chiều có nhãn) và cấu trúc DataFrame (bảng 2 chiều). Khác với mảng trong C++ hay Java, DataFrame cho phép chứa nhiều kiểu dữ liệu khác nhau (integer, float, string, datetime) trong cùng một đối tượng nhưng khác cột. Đây chính là yếu tố biến nó trở thành tiêu chuẩn vàng trong các dự án phân tích dữ liệu thực tế hiện nay.
Cài đặt và thiết lập môi trường chuẩn
Để đảm bảo hiệu suất và tránh xung đột thư viện, tôi khuyến nghị sử dụng Python 3.10 trở lên. Trong các môi trường chuyên nghiệp, việc quản lý thư viện qua pip hoặc conda là bắt buộc để duy trì tính nhất quán của project.
Cài đặt qua Terminal/Command Prompt:
# Cài đặt phiên bản ổn định mới nhất (khuyến nghị dùng virtualenv)
pip install pandas numpy matplotlibImport thư viện vào project:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Kiểm tra phiên bản để đảm bảo tính thương thích
print(f"Pandas Version: {pd.__version__}")
# Output kỳ vọng: 2.x.x hoặc mới hơnViệc sử dụng bí danh pd là một tiêu chuẩn cộng đồng giúp code của bạn dễ đọc và chuyên nghiệp hơn. Nếu bạn làm việc trên Jupyter Notebook, việc kết hợp với Matplotlib sẽ giúp trực quan hóa kết quả ngay sau khi xử lý.
Khởi tạo và đọc dữ liệu chuyên sâu
thư viện pandas trong python hỗ trợ đọc dữ liệu từ rất nhiều nguồn: SQL, Excel, JSON, Parquet (dành cho Big Data) và phổ biến nhất là CSV.
Đọc file CSV với các tham số tối ưu
Hàm read_csv có hơn 50 tham số, nhưng trong thực tế, bạn cần làm chủ các tham số sau để tránh lỗi tràn bộ nhớ hoặc sai định dạng:
try:
path = './people.csv'
peoples_df = pd.read_csv(
path,
encoding='utf-8',
sep=',',
index_col='person_ID', # Chuyển cột ID thành index để truy xuất O(1)
usecols=['person_ID', 'name', 'age', 'title', 'email'], # Chỉ load cột cần thiết để tiết kiệm RAM
dtype={'age': np.int8} # Tối ưu kiểu dữ liệu (age không cần int64)
)
print("Nạp dữ liệu thành công!")
print(peoples_df.head(5))
except FileNotFoundError:
print("Lỗi: Không tìm thấy file. Hãy kiểm tra lại đường dẫn tuyệt đối.")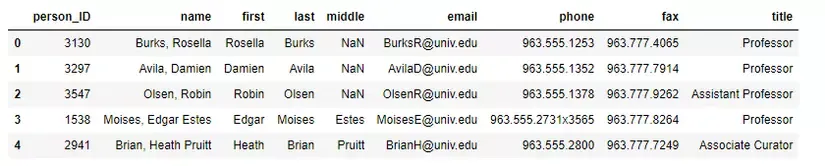
Lưu ý chuyên gia: Khi làm việc với file lớn (>1GB), hãy sử dụng tham số chunksize để đọc dữ liệu theo từng phần, tránh hiện tượng Memory Error.
Khởi tạo DataFrame từ cấu trúc dữ liệu thuần
Đôi khi bạn cần chuyển đổi kết quả từ API (thường là list of dicts) sang DataFrame:
data_api = [
{"name": "Nguyen Van A", "age": 25, "city": "Hanoi"},
{"name": "Tran Thi B", "age": 30, "city": "HCM"}
]
# Tạo DataFrame từ list dictionary
df_manual = pd.DataFrame(data_api)
# Complexity: O(NM) với N là số hàng, M là số cột
print(df_manual)Thao tác truy xuất dữ liệu tối ưu (Indexing)
Một trong những sai lầm lớn nhất của beginner khi dùng thư viện pandas trong python là nhầm lẫn giữa .loc và .iloc. Sự sai khác này không chỉ ở cú pháp mà còn ở bản chất truy xuất bộ nhớ.
.loc: Truy cập dựa trên nhãn (label). Độ phức tạp trung bình $O(1)$ nếu index được hash tốt..iloc: Truy cập dựa trên vị trí nguyên số (integer position). Tương tự như truy cập mảng trong C.
# 1. Lọc theo hàng và cột cụ thể (người có tuổi > 25)
# Sử dụng Boolean Indexing - Phép toán vector hóa
high_age_df = peoples_df.loc[peoples_df['age'] > 25, ['name', 'email']]
# 2. Truy xuất 5 hàng đầu tiên và 3 cột đầu tiên
subset_idx = peoples_df.iloc[0:5, 0:3]
# 3. Sử dụng Str accessor để lọc chuỗi (Rất hữu ích cho xử lý dữ liệu)
rosella_df = peoples_df[peoples_df['name'].str.contains('Rosella', case=False)]Pitfall thực tế: Tránh sử dụng kiểu truy cập theo chuỗi như df['col'][0]. Điều này tạo ra một “SettingWithCopyWarning”. Hãy luôn trung thành với .loc hoặc .at để đảm bảo đang thao tác trực tiếp trên vùng nhớ của DataFrame gốc.
Kỹ thuật xử lý dữ liệu và dọn dẹp (Cleaning)
Dữ liệu thực tế luôn “bẩn”. thư viện pandas trong python cung cấp các công cụ mạnh mẽ để xử lý các giá trị khuyết thiếu (NaN) và dữ liệu nhiễu.
Xử lý giá trị NULL (Missing Data)
# Kiểm tra tỉ lệ dữ liệu trống trên mỗi cột
null_report = peoples_df.isnull().sum() / len(peoples_df) 100
print(f"Tỉ lệ trống:n{null_report}")
# Chiến lược 1: Xóa bỏ hàng trống (Chỉ dùng khi dữ liệu trống < 5%)
# peoples_df.dropna(inplace=True)
# Chiến lược 2: Điền giá trị trung bình (Nên dùng cho phân tích thống kê)
peoples_df['age'] = peoples_df['age'].fillna(peoples_df['age'].mean())
# Chiến lược 3: Điền giá trị cố định hoặc forward fill
peoples_df['title'] = peoples_df['title'].fillna('Unknown')Việc lựa chọn chiến lược xử lý dữ liệu khuyết thiếu phụ thuộc vào ý nghĩa nghiệp vụ. Ví dụ, trong ngành tài chính, việc điền sai giá trị có thể dẫn đến lệch kết quả dự báo nghiêm trọng.
Thêm và xóa cột logic
# Thêm cột mới dựa trên logic điều kiện (O(N))
# Sử dụng np.where để đạt hiệu năng vector hóa tối đa
peoples_df['age_group'] = np.where(peoples_df['age'] < 18, 'Minor', 'Adult')
# Xóa các cột không cần thiết để giải phóng bộ nhớ
peoples_df = peoples_df.drop(columns=['fax', 'new_column'], errors='ignore')Phân tích thống kê và GroupBy
Sức mạnh thực sự của thư viện pandas trong python nằm ở cơ chế Split-Apply-Combine. Đây là quy trình: chia dữ liệu thành các nhóm -> áp dụng hàm tính toán -> gộp kết quả.
# Thống kê mô tả các cột số
stats = peoples_df.describe()
print(stats)
# Gom nhóm theo chức danh và tính tuổi trung bình
# Độ phức tạp: O(N) do sử dụng Hash Map bên dưới
title_group = peoples_df.groupby('title')['age'].agg(['mean', 'median', 'count'])
# Lọc các nhóm có số lượng thành viên > 2
large_groups = title_group[title_group['count'] > 2]
print(large_groups)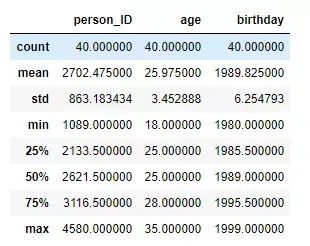
Trong các bài toán xử lý dữ liệu lớn, hãy ưu tiên dùng các hàm gộp có sẵn như .sum(), .mean() thay vì dùng .apply(lambda x: ...) vì các hàm built-in được tối ưu bằng mã Cython.
Kết hợp dữ liệu: Merge, Join và Concat
Trong thực tế, dữ liệu thường nằm rải rác ở nhiều bảng. Việc kết hợp chúng đòi hỏi sự hiểu biết về quan hệ dữ liệu (1-1, 1-n, n-n).
- Concat: Nối các DataFrame theo chiều dọc hoặc ngang (như UNION trong SQL).
- Merge: Kết hợp dựa trên một hoặc nhiều khóa chung (như JOIN trong SQL).
# Giả sử có 2 DF: df_info và df_salary
# inner join: lấy phần giao giữa 2 bảng
# left join: giữ nguyên bảng bên trái, bảng bên phải không có thì để NaN
combined_df = pd.merge(df_info, df_salary, on='person_ID', how='inner')
# Độ phức tạp: O(N + M) nếu merge trên index, O(NM) nếu merge trên cột không indexTối ưu hiệu năng bộ nhớ cho tập dữ liệu lớn
Khi sử dụng thư viện pandas trong python để xử lý hàng chục triệu dòng, RAM sẽ nhanh chóng cạn kiệt. Một mẹo nhỏ từ kinh nghiệm thực chiến của tôi là hạ cấp (downcast) kiểu dữ liệu.
def optimize_memory(df):
start_mem = df.memory_usage().sum() / 10242
for col in df.columns:
col_type = df
.dtype
if col_type != object:
c_min = df
.min()
c_max = df
.max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df
= df
.astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df
= df
.astype(np.int16)
end_mem = df.memory_usage().sum() / 10242
print(f'Memory reduced by {100 (start_mem - end_mem) / start_mem:.2f}%')
return df
peoples_df = optimize_memory(peoples_df)Việc chuyển đổi từ int64 sang int8 có thể giảm dung lượng lưu trữ tới 8 lần mà không làm mất dữ liệu nếu dải giá trị cho phép. Đây là kỹ thuật sống còn khi triển khai các mô hình Machine Learning trên Cloud với tài nguyên hạn chế.
Xuất dữ liệu và lưu trữ kết quả
Bất kỳ quy trình xử lý dữ liệu nào cũng kết thúc bằng việc lưu lại kết quả để phục vụ báo cáo hoặc các ứng dụng khác.
# Lưu ra file CSV không kèm index
peoples_df.to_csv('cleaned_data.csv', index=False, encoding='utf-8-sig')
# Lưu ra Excel (yêu cầu thư viện openpyxl)
# peoples_df.to_excel('report.xlsx', sheet_name='Data_2023')
# Lưu ra định dạng Parquet để tối ưu tốc độ đọc cho các lần sau
# peoples_df.to_parquet('data.parquet') Định dạng .parquet ngày càng được ưa chuộng thay thế cho CSV nhờ khả năng nén cực cao và tốc độ truy xuất cột vượt trội, đặc biệt phù hợp trong môi trường sản xuất.
thư viện pandas trong python là một công cụ không thể thiếu đối với bất kỳ ai muốn tiến xa trong ngành dữ liệu. Bằng cách hiểu rõ cơ chế quản lý bộ nhớ, sự khác biệt giữa các phương thức chọn lọc dữ liệu và kỹ thuật vector hóa, bạn không chỉ viết được code chạy đúng màu mà còn phải chạy nhanh và hiệu quả. Hãy tiếp tục thực hành với các bộ dữ liệu lớn trên Kaggle để thuần thục các kỹ năng nâng cao hơn.
Nguồn tham khảo:
- Pandas Official Documentation: pandas.pydata.org
- Python for Data Analysis by Wes McKinney (Tác giả của Pandas).
Cập nhật lần cuối 03/03/2026 by Hiếu IT