Trong lĩnh vực máy học (Machine Learning), thuật toán knn là gì luôn là câu hỏi đầu tiên mà các lập trình viên bắt đầu tiếp cận với trí tuệ nhân tạo cần giải đáp. K-Nearest Neighbors (KNN) không chỉ là một thuật toán phân loại cơ bản mà còn là nền tảng quan trọng để hiểu về các mô hình học dựa trên thực thể (Instance-based learning). Với hơn 10 năm kinh nghiệm phát triển hệ thống xử lý dữ liệu, tôi nhận thấy KNN vẫn duy trì được giá trị cốt lõi nhờ tính đơn giản tuyệt đối nhưng mang lại hiệu quả đáng kinh ngạc trong các bài toán thực tế như gợi ý sản phẩm hoặc nhận diện hình ảnh quy mô nhỏ.
Nguyên lý hoạt động cốt lõi của thuật toán k-nearest neighbors
Để hiểu rõ thuật toán knn là gì, chúng ta cần nắm vững triết lý “Gần mực thì đen, gần đèn thì sáng”. Đây là một thuật toán thuộc nhóm Supervised Learning (học có giám sát), nhưng khác với Support Vector Machine (SVM) hay Neural Networks, KNN không xây dựng một mô hình toán học tường minh trong quá trình huấn luyện. Thay vào đó, nó lưu trữ toàn bộ tập dữ liệu huấn luyện và chỉ thực hiện tính toán khi có dữ liệu mới cần dự đoán.
Thuật toán này được phân loại là một Lazy Learning algorithm. Điều này có nghĩa là giai đoạn huấn luyện (training phase) diễn ra cực nhanh, gần như chỉ là việc nạp dữ liệu vào bộ nhớ. Tuy nhiên, cái giá phải trả là giai đoạn dự đoán (inference phase) sẽ tốn kém chi phí tính toán vì máy tính phải so sánh thực thể mới với tất cả thực thể cũ để tìm ra “hàng xóm” gần nhất.
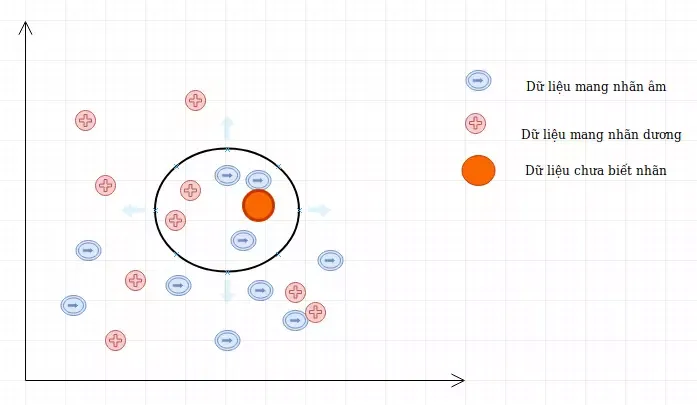
3 Công thức tính khoảng cách phổ biến trong KNN
Đo lường sự tương đồng là yếu tố sống còn khi thực thi thuật toán knn là gì. Tùy thuộc vào bản chất của đặc trưng (features) mà chúng ta lựa chọn các hàm đo khoảng cách khác nhau trong không gian vector.
- Khoảng cách Euclidean: Đây là thước đo phổ biến nhất, tính theo đường thẳng giữa hai điểm trong không gian n chiều. Công thức: $d(x, y) = sqrt{sum_{i=1}^{n} (x_i – y_i)^2}$. Phù hợp nhất cho dữ liệu có phân phối liên tục.
- Khoảng cách Manhattan: Tính tổng trị tuyệt đối của hiệu các tọa độ. Công thức: $d(x, y) = sum_{i=1}^{n} |x_i – y_i|$. Thường dùng khi các đặc trưng không có sự liên quan trực tiếp về mặt hình học.
- Khoảng cách Minkowski: Đây là dạng tổng quát hóa của cả Euclidean và Manhattan với tham số $p$. Khi $p=2$, nó trở thành Euclidean, khi $p=1$ nó là Manhattan.
Khi lập trình thực tế, việc chọn sai công thức tính khoảng cách có thể dẫn đến hiện tượng sai lệch dự đoán nghiêm trọng, đặc biệt khi các thuộc tính có đơn vị đo lường khác nhau. Do đó, bước chuẩn hóa dữ liệu (Scaling/Normalization) là bắt buộc trước khi tính toán.
Quy trình 5 bước thực thi thuật toán knn là gì
Một quy trình chuẩn hoá để triển khai KNN bao gồm các bước logic chặt chẽ sau:
- Bước 1: Xác định tham số $K$ (số lượng hàng xóm gần nhất) và hàm đo khoảng cách phù hợp.
- Bước 2: Tính toán khoảng cách từ điểm dữ liệu mới (test point) đến tất cả các điểm trong tập huấn luyện (training set).
- Bước 3: Sắp xếp các khoảng cách này theo thứ tự tăng dần để tìm ra $K$ điểm gần nhất.
- Bước 4: Thống kê nhãn của $K$ điểm này. Nếu là bài toán phân loại (Classification), ta dùng cơ chế biểu quyết số đông (Majority Voting). Nếu là bài toán hồi quy (Regression), ta lấy trung bình cộng.
- Bước 5: Gán nhãn hoặc giá trị dự đoán cho điểm dữ liệu mới.
Trong thực tế, người ta thường chọn $K$ là một số lẻ để tránh tình trạng hòa vốn (tie-break) khi biểu quyết giữa các lớp.
Cách chọn tham số K tối ưu để tránh Overfitting
Việc lựa chọn tham số $K$ đóng vai trò quyết định đến độ chính xác của thuật toán knn là gì. Nếu chọn $K$ quá nhỏ (ví dụ $K=1$), mô hình sẽ cực kỳ nhạy cảm với các điểm nhiễu (noise), dẫn đến hiện tượng overfitting. Ngược lại, nếu $K$ quá lớn, mô hình sẽ trở nên quá “mềm mại”, bỏ qua các đặc trưng cục bộ và dẫn đến underfitting.
Kỹ thuật tốt nhất để tìm $K$ là sử dụng Cross-Validation (kiểm chéo). Thông thường, chúng ta sẽ thử nghiệm các giá trị $K$ trong khoảng từ 1 đến $sqrt{n}$ (với $n$ là số lượng mẫu dữ liệu) và chọn giá trị có độ lỗi thấp nhất trên tập validation.
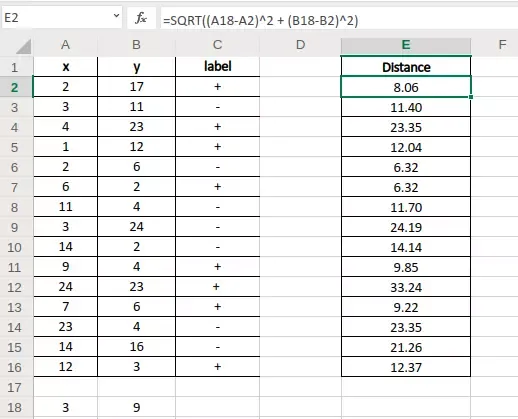
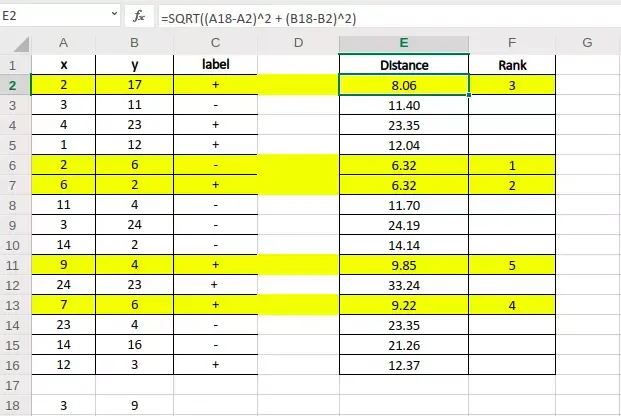
Triển khai KNN với Python từ Scikit-learn đến Scratch
Dưới đây là một ví dụ thực tế triển khai thuật toán knn là gì bằng ngôn ngữ Python (phiên bản 3.10+). Tôi sẽ cung cấp hai phương pháp: Tự xây dựng (Scratch) để hiểu bản chất và dùng thư viện Scikit-learn cho môi trường production.
Cách 1: Triển khai KNN từ Scratch (Pure Python & Numpy)
Dưới đây là logic cơ bản giúp bạn nắm rõ cách tương tác với đại số tuyến tính trong KNN.
import numpy as np from collections import Counter class KNNFromScratch: def __init__(self, k=3): self.k = k def fit(self, X, y): # KNN là Lazy Learning nên chỉ cần lưu trữ data self.X_train = X self.y_train = y def predict(self, X): predictions = [self._predict(x) for x in X] return np.array(predictions) def _predict(self, x): # 1. Tính khoảng cách Euclidean distances = [np.sqrt(np.sum((x - x_train)2)) for x_train in self.X_train] # 2. Tìm K hàng xóm gần nhất (lấy index) k_indices = np.argsort(distances)[:self.k] # 3. Lấy nhãn của K hàng xóm k_nearest_labels = [self.y_train[i] for i in k_indices] # 4. Biểu quyết số đông most_common = Counter(k_nearest_labels).most_common(1) return most_common[0][0] # Dữ liệu mẫu (Input: Toạ độ, Output: Nhãn 0 hoặc 1) X_train = np.array([[1, 2], [2, 3], [3, 1], [6, 7], [7, 8], [8, 6]]) y_train = np.array([0, 0, 0, 1, 1, 1]) X_new = np.array([[3, 9]]) # Điểm A(3,9) cần dự đoán model = KNNFromScratch(k=3) model.fit(X_train, y_train) prediction = model.predict(X_new) print(f"Kết quả dự đoán nhãn cho điểm A(3,9) là: {prediction[0]}") # Output mẫu: Kết quả dự đoán nhãn cho điểm A(3,9) là: 1Cách 2: Triển khai chuyên nghiệp với Scikit-learn (Industry Standard)
Trong các dự án thực tế, chúng ta nên sử dụng thư viện mạnh mẽ để tối ưu tốc độ tính toán.
from sklearn.neighbors import KNeighborsClassifier from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split # Giả sử X, y là tập dữ liệu thực tế # 1. Pipeline bắt buộc: Scaling là cực kỳ quan trọng đối với KNN scaler = StandardScaler() X_scaled = scaler.fit_transform(X_train) # 2. Khởi tạo mô hình với bộ tham số tối ưu # n_neighbors tương đương với K knn_model = KNeighborsClassifier(n_neighbors=5, metric='minkowski', p=2) # 3. Huấn luyện knn_model.fit(X_scaled, y_train) # 4. Dự đoán X_new_scaled = scaler.transform(X_new) result = knn_model.predict(X_new_scaled)Phân tích độ phức tạp thuật toán knn là gì (Big O)
Một chuyên gia cần hiểu rõ chi phí vận hành của mô hình. Trong phương pháp Brute Force truyền thống:
- Độ phức tạp thời gian huấn luyện: $O(1)$ – Gần như không làm gì ngoài lưu trữ dữ liệu.
- Độ phức tạp thời gian dự đoán: $O(N times D)$, trong đó $N$ là số lượng mẫu và $D$ là số lượng đặc trưng. Khi dữ liệu lên hàng triệu bản ghi, việc tính toán này trở nên cực kỳ chậm chạp.
- Độ phức tạp không gian: $O(N times D)$ vì phải nạp toàn bộ tập dữ liệu vào RAM.
Để khắc phục nhược điểm về tốc độ, các thư viện như Scikit-learn sử dụng các cấu trúc dữ liệu nâng cao như KD-Tree hoặc Ball Tree để giảm độ phức tạp dự đoán xuống còn $O(D log N)$.
So sánh KNN với các thuật toán phân loại khác
Mỗi thuật toán đều có thế mạnh riêng, bảng dưới đây giúp bạn định vị rõ hơn vị trí của thuật toán knn là gì trong hệ sinh thái máy học.
| Tiêu chí | KNN (K-Nearest Neighbors) | SVM (Support Vector Machine) | Logistic Regression |
|---|---|---|---|
| Loại hình | Non-parametric, Lazy Learning | Parametric, Eager Learning | Parametric, Eager Learning |
| Tốc độ train | Rất nhanh | Bình thường | Nhanh |
| Tốc độ test | Rất chậm | Nhanh | Rất nhanh |
| Dữ liệu nhiễu | Nhạy cảm cao | Khá ổn định | Ổn định |
| Khả năng giải thích | Dễ hiểu (trực quan) | Khó hiểu (toán học phức tạp) | Dễ hiểu (xác suất) |
Khám phá ưu và nhược điểm thực tế của KNN
Dựa trên kinh nghiệm debug hàng trăm mô hình, tôi đúc kết những điểm quan trọng về thuật toán knn là gì như sau:
Ưu điểm:
- Không cần giả định về phân phối của dữ liệu (Non-parametric).
- Cực kỳ hiệu quả khi tập huấn luyện được cập nhật thường xuyên (Online learning).
- Chỉ có 2 tham số chính cần điều chỉnh: $K$ và hàm khoảng cách.
Nhược điểm:
- Rất nhạy cảm với dữ liệu thiếu (Missing values) và dữ liệu nhiễu (Outliers).
- Gặp khó khăn với “lời nguyền đa chiều” (Curse of Dimensionality): Khi số lượng đặc trưng $D$ tăng quá lớn, khoảng cách giữa các điểm trở nên không còn ý nghĩa.
- Chi phí bộ nhớ cao: Bạn cần nhiều RAM để chứa toàn bộ Dataset.
Ứng dụng thực tế của thuật toán k-nearest neighbors
Dù đơn giản, thuật toán knn là gì vẫn đang âm thầm vận hành trong nhiều hệ thống chúng ta dùng hàng ngày.
- Hệ thống gợi ý (Recommender Systems): Tìm kiếm những người dùng có hành vi tương đồng để giới thiệu phim (Netflix) hoặc nhạc (Spotify).
- Y sinh (Biomedicine): Phân loại nhóm người bệnh dựa trên các chỉ số sinh hóa tương đồng để đưa ra phác đồ điều trị.
- Phát hiện gian lận (Fraud Detection): Xác định các giao dịch có đặc điểm bất thường so với “hàng xóm” là các giao dịch hợp lệ.
Để tối ưu hóa KNN trong project thực tế, lời khuyên của tôi là bạn hãy luôn kết hợp với các kỹ thuật giảm chiều dữ liệu như PCA (Principal Component Analysis) để loại bỏ các thuộc tính dư thừa, từ đó tăng tốc độ tính toán đáng kể.
Việc hiểu rõ thuật toán knn là gì chính là bước đệm hoàn hảo để bạn tiến xa hơn vào thế giới AI. Dù tồn tại những hạn chế về tốc độ khi xử lý Big Data, nhưng sự minh bạch và tính trực quan của KNN vẫn khiến nó trở thành công cụ không thể thiếu trong túi đồ nghề của bất kỳ kỹ sư dữ liệu nào. Nếu bạn đang bắt đầu với một tập dữ liệu nhỏ và cần một kết quả phân loại nhanh chóng, đừng ngần ngại chọn KNN làm model baseline đầu tiên.
Tham khảo thêm:
- Documentations của thư viện Scikit-learn về Neighbors.
- Sách “Pattern Recognition and Machine Learning” – Christopher Bishop.
Cập nhật lần cuối 03/03/2026 by Hiếu IT