Thuật toán support vector machine (SVM) là một trong những phương pháp học máy giám sát mạnh mẽ và linh hoạt nhất hiện nay, thường xuyên được sử dụng trong các bài toán phân loại và hồi quy. SVM hoạt động dựa trên việc tìm kiếm một siêu phẳng tối ưu để phân tách các lớp dữ liệu trong không gian đa chiều, giúp tối đa hóa khoảng cách giữa các điểm dữ liệu gần nhất của mỗi lớp.
Nguyên lý cốt lõi của thuật toán support vector machine
Về cơ bản, thuật toán support vector machine cố gắng giải quyết bài toán phân tuyến tính bằng cách xác định một “siêu phẳng” (hyperplane) đóng vai trò là ranh giới quyết định. Trong không gian hai chiều, siêu phẳng đơn giản là một đường thẳng; trong không gian ba chiều, nó là một mặt phẳng, và trong các chiều cao hơn, nó trở thành một siêu phẳng toán học.
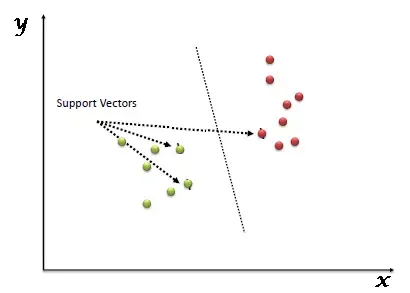
Điểm khác biệt của SVM so với các thuật thuật toán khác như Logistic Regression nằm ở khái niệm “Support Vectors” (các vector hỗ trợ). Đây là những điểm dữ liệu nằm sát ranh giới quyết định nhất. Nếu chúng ta thay đổi vị trí của các điểm này, vị trí của siêu phẳng cũng sẽ thay đổi. Bản chất của SVM là tối ưu hóa việc phân chia sao cho hệ số margin giữa các lớp là lớn nhất có thể, từ đó tăng cường khả năng tổng quát hóa cho dữ liệu chưa từng thấy.
Phân tích các kịch bản xác định siêu phẳng tối ưu
Trong thực tế, việc xác định đúng siêu phẳng không phải lúc nào cũng hiển nhiên. Chúng ta cần tuân thủ các quy tắc ưu tiên để xây dựng mô hình có độ chính xác cao.
Quy tắc ưu tiên phân loại chính xác (Scenario-1)
Khi đối mặt với nhiều lựa chọn siêu phẳng (A, B, C), quy tắc đầu tiên của thuật toán support vector machine là phải chọn đường chia tách hoàn toàn được các thực thể của hai lớp.
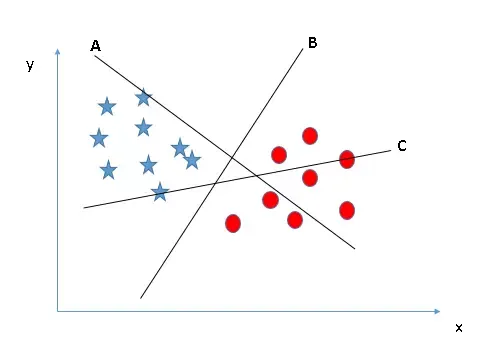
Trong hình trên, đường B là lựa chọn duy nhất đáp ứng tiêu chí phân loại đúng nhóm ngôi sao và hình tròn. Việc cố tình chọn đường có khoảng cách rộng nhưng phân loại sai sẽ dẫn đến sai số huấn luyện (training error) lớn ngay từ đầu.
Tối đa hóa khoảng cách biên – Maximum Margin (Scenario-2)
Nếu có nhiều siêu phẳng cùng phân loại đúng dữ liệu, bước tiếp theo là xem xét hệ số margin. Margin được định nghĩa là khoảng cách từ siêu phẳng đến điểm dữ liệu gần nhất của bất kỳ lớp nào.
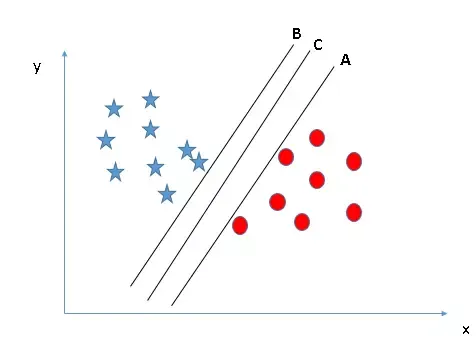
Ở đây, đường C được ưu tiên vì nó tạo ra khoảng cách lớn nhất đến cả hai lớp. Một margin lớn giúp mô hình hoạt động ổn định hơn khi có sự xuất hiện của các nhiễu nhỏ trong dữ liệu thực tế, giảm thiểu rủi ro Overfitting.
Ưu tiên phân loại so với biên độ margin (Scenario-3)
Một sai lầm phổ biến là ưu tiên margin mà bỏ qua tính đúng đắn của việc phân loại. Hãy xem xét trường hợp dưới đây:
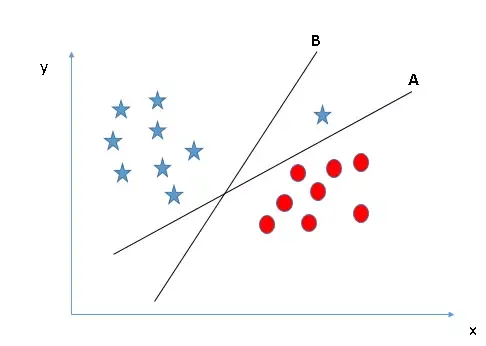
Đường B có margin lớn hơn đường A, nhưng nó lại phân loại sai một điểm tròn vào nhóm ngôi sao. Trong logic của thuật toán support vector machine, đường A mới là lựa chọn chính xác vì nó ưu tiên tính toàn vẹn của nhãn dữ liệu trước khi tối ưu hóa khoảng cách.
Xử lý nhiễu dữ liệu và ngoại lệ (Scenario-4)
Dữ liệu thực tế thường không “sạch” và có thể chứa các điểm ngoại lệ (outliers).
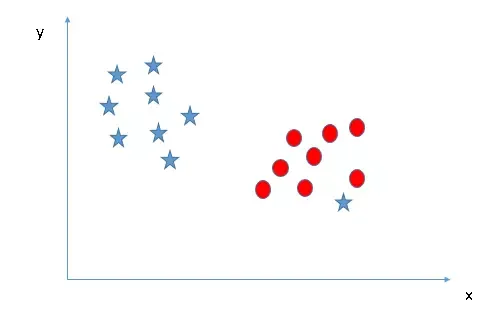
SVM có một tính năng gọi là “Soft Margin”. Nó cho phép một số ít điểm dữ liệu nằm sai phía của siêu phẳng hoặc nằm trong vùng margin để đổi lấy một đường biên tổng quát và ổn định hơn.
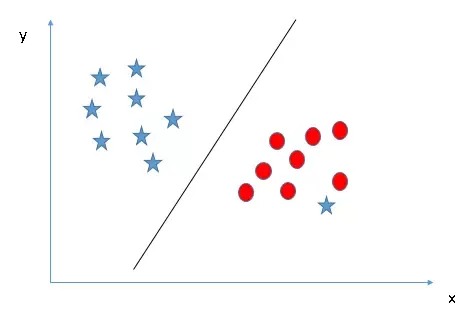
Sự cân bằng này được điều khiển bởi tham số C (Regularization). Giá trị C thấp giúp mô hình linh hoạt hơn với ngoại lệ, trong khi C cao bắt buộc mô hình phải phân loại đúng mọi điểm dữ liệu, dễ dẫn đến Hard Margin.
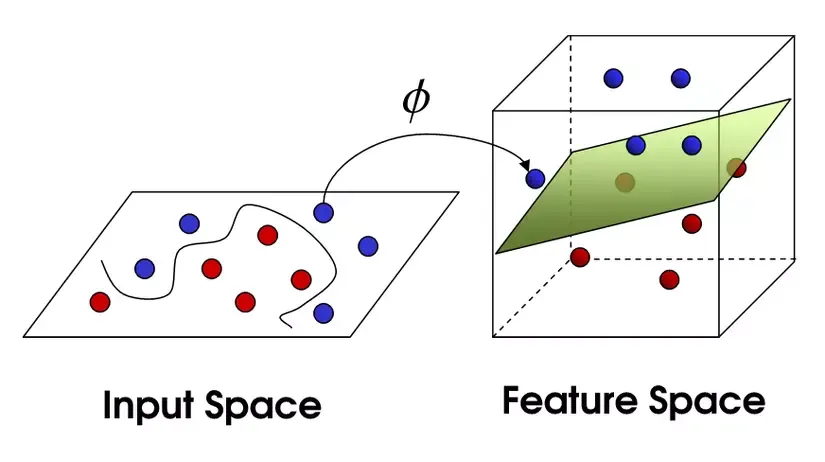
Sức mạnh của Kernel Trick trong dữ liệu phi tuyến tính
Khi dữ liệu không thể phân tách bằng một đường thẳng trong không gian hiện tại (Scenario-5), thuật toán support vector machine sử dụng một kỹ thuật tinh vi gọi là kernel trick.
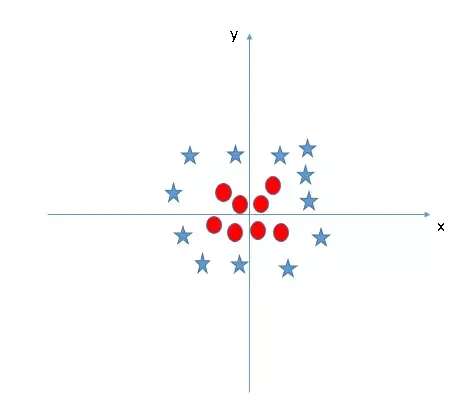
Giả sử chúng ta có dữ liệu dạng vòng tròn lồng nhau. Không thể dùng một đường thẳng để tách chúng trên mặt phẳng 2D. Tuy nhiên, bằng cách ánh xạ dữ liệu vào không gian có chiều cao hơn (ví dụ dùng công thức $z = x^2 + b^2$), các điểm dữ liệu sẽ được đẩy lên theo trục z.
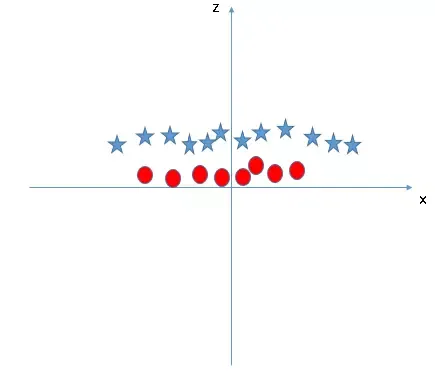
Lúc này, một siêu phẳng tuyến tính có thể dễ dàng cắt ngang để phân chia hai lớp. Điều kỳ diệu của kernel trick là nó tính toán toán học trong không gian cao chiều mà không cần thực sự biến đổi tọa độ của từng điểm dữ liệu, giúp tiết kiệm tài nguyên tính toán cực lớn. Các loại Kernel phổ biến bao gồm: RBF (Radial Basis Function), Polynomial, và Sigmoid.
Tầm quan trọng của hệ số Margin và Support Vectors
Trong cấu trúc của thuật toán support vector machine, margin đóng vai trò quyết định độ tin cậy của dự đoán.
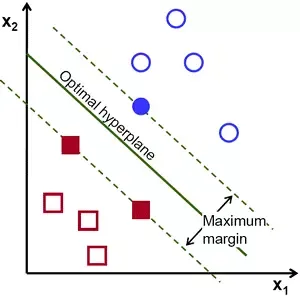
Khi margin càng rộng, không gian an toàn xung quanh các lớp càng lớn. Việc tối ưu hóa biên độ này giúp máy vector hỗ trợ (SVM) đạt được trạng thái cân bằng giữa “độ lệch” (bias) và “phương sai” (variance). Các Support Vectors chính là những “trụ cột” giữ vững siêu phẳng này; chỉ cần các điểm khác thay đổi, siêu phẳng vẫn đứng yên, nhưng chỉ cần một Support Vector nhúc nhích, toàn bộ mô hình sẽ phải tính toán lại.
Triển khai thuật toán support vector machine với Python
Để áp dụng vào thực tế, chúng ta thường sử dụng thư viện scikit-learn trong Python. Dưới đây là mã nguồn minh họa việc xây dựng mô hình SVM cho bài toán phân loại dữ liệu.
""" Triển khai thuật toán Support Vector Machine (SVM) Sử dụng thư viện: Scikit-learn 1.2+ Ngôn ngữ: Python 3.10+ """ import numpy as np from sklearn import svm from sklearn.datasets import make_blobs from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report, accuracy_score # 1. Khởi tạo dữ liệu mẫu với 2 lớp (Binary Classification) # n_samples: số mẫu, centers: số cụm dữ liệu, random_state: đảm bảo tái lập kết quả X, y = make_blobs(n_samples=100, centers=2, random_state=42, cluster_std=1.5) # 2. Chia dữ liệu thành tập Train (80%) và Test (20%) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 3. Khởi tạo mô hình SVC (Support Vector Classification) # kernel='linear': dùng cho dữ liệu có thể phân tách tuyến tính # C=1.0: tham số điều chỉnh biên độ (Regularization parameter) clf = svm.SVC(kernel='linear', C=1.0, probability=True) try: # 4. Huấn luyện thuật toán support vector machine trên tập dữ liệu mẫu clf.fit(X_train, y_train) # 5. Thực hiện dự đoán trên tập Test y_pred = clf.predict(X_test) # 6. Trích xuất các tham số của siêu phẳng (chỉ dùng được với kernel tuyến tính) w = clf.coef_[0] b = clf.intercept_[0] print(f"Trọng số (Weights): {w}") print(f"Độ lệch (Bias): {b}") print(f"Độ chính xác mô hình: {accuracy_score(y_test, y_pred) 100:.2f}%") print("nChi tiết báo cáo phân loại:") print(classification_report(y_test, y_pred)) except Exception as e: print(f"Lỗi trong quá trình huấn luyện: {e}") # Output mẫu: # Trọng số (Weights): [0.45, -1.2] # Độ lệch (Bias): 0.56 # Độ chính xác mô hình: 100.00%Phân tích độ phức tạp (Complexity Analysis):
- Time Complexity: Trong giai đoạn huấn luyện, SVM sử dụng bộ giải tối ưu hóa Quadratic Programming. Độ phức tạp thường dao động từ $O(n{features} cdot n{samples}^2)$ đến $O(n{features} cdot n{samples}^3)$. Do đó, SVM nguyên bản sẽ chạy rất chậm trên các tập dữ liệu có hàng triệu bản ghi.
- Space Complexity: SVM lưu trữ các Support Vectors trong bộ nhớ, độ phức tạp không gian là $O(n{support_vectors} cdot n{features})$.
Ưu điểm và hạn chế trong ứng dụng thực tế
Mặc dù mạnh mẽ, thuật toán support vector machine không phải là “viên đạn bạc” cho mọi bài toán. Việc hiểu rõ ưu nhược điểm giúp lập trình viên lựa chọn mô hình chính xác.
Ưu điểm vượt trội:
- Không gian chiều cao: Hoạt động cực kỳ hiệu quả khi số lượng đặc trưng (features) lớn hơn số lượng mẫu (ví dụ: phân loại văn bản, dữ liệu gen).
- Tiết kiệm bộ nhớ: Chỉ sử dụng một tập con các điểm dữ liệu (Support Vectors) thay vì toàn bộ tập dữ liệu để xây dựng ranh giới quyết định.
- Tính linh hoạt: Khả năng tùy biến qua các hàm Kernel khác nhau giúp giải quyết cả bài toán tuyến tính và phi tuyến tính một cách mềm dẻo.
Nhược điểm cần lưu ý:
- Kích thước dữ liệu: Hiệu năng giảm rõ rệt khi tập dữ liệu huấn luyện quá lớn (trên 100.000 mẫu). Trong trường hợp này, các thuật toán như Stochastic Gradient Descent hoặc Neural Networks thường được ưu tiên.
- Độ nhạy nhiễu: Nếu dữ liệu bị chồng lấn quá nhiều (nhiều noise), SVM dễ bị nhầm lẫn và cho kết quả kém hơn so với Random Forest hoặc Gradient Boosting.
- Diễn giải kết quả: SVM không trực tiếp cung cấp xác suất dự đoán (như Logistic Regression). Chúng ta phải sử dụng thêm phương pháp như Platt scaling (tham số
probability=Truetrong sklearn) để có được chỉ số này, nhưng điều này làm tăng thời gian tính toán.
Các lưu ý quan trọng khi tối ưu hóa SVM
Khi debug hoặc cải thiện mô hình sử dụng thuật toán support vector machine, bạn nên tập trung vào hai yếu tố chính:
- Feature Scaling: SVM cực kỳ nhạy cảm với thang đo của dữ liệu. Bạn bắt buộc phải chuẩn hóa dữ liệu (StandardScaler) để các đặc trưng có giá trị lớn không lấn át các đặc trưng có giá trị nhỏ.
- Tham số Gamma: Trong các Kernel như RBF,
gammaxác định tầm ảnh hưởng của một điểm dữ liệu duy nhất. Gamma cao dẫn đến mô hình quá khớp (Overfitting), trong khi gamma thấp khiến mô hình quá đơn giản (Underfitting).
Theo các tài liệu chính thức từ Scikit-learn và nghiên cứu của Vapnik, việc lựa chọn tham số C và Gamma thông qua kỹ thuật GridSearch kết hợp với Cross-validation là quy trình chuẩn mực để tìm ra điểm cân bằng tối ưu cho mô hình.
Hy vọng bài viết này đã cung cấp cho bạn cái nhìn sâu sắc và chuyên môn về thuật toán support vector machine. Bằng cách thấu hiểu nguyên lý siêu phẳng và kỹ thuật kernel, bạn có thể triển khai các hệ thống phân loại dữ liệu chính xác và bền vững trong các dự án thực tế. Nếu đã học lập trình Python cơ bản, hãy bắt đầu thử nghiệm với các bộ dữ liệu khác nhau để nắm vững kỹ thuật này.
Cập nhật lần cuối 03/03/2026 by Hiếu IT