Trong khoa học máy tính, việc hiểu rõ thuật toán tìm kiếm là gì đóng vai trò then chốt khi xử lý dữ liệu lớn. Đây là tập hợp các chỉ dẫn logic nhằm xác định vị trí của một phần tử trong cấu trúc dữ liệu. Bài viết này cung cấp cái nhìn chuyên sâu về cơ chế vận hành, độ phức tạp thời gian và các kỹ thuật tối ưu mã nguồn thực tế.
Bản chất hệ thống của thuật toán tìm kiếm là gì?
Về cốt lõi, thuật toán tìm kiếm là gì? Đó là quá trình lấy một khóa (key) làm đầu vào và trả về vị trí của dữ liệu tương ứng. Trong môi trường phần mềm hiện đại, hiệu suất tìm kiếm quyết định tốc độ phản hồi của toàn bộ hệ thống back-end.
Hoạt động tìm kiếm không chỉ giới hạn trong mảng (array) hay danh sách (list). Nó mở rộng sang các cấu trúc phức tạp như cây nhị phân (Binary Tree), đồ thị (Graph) hoặc bảng băm (Hash Table). Mỗi loại cấu trúc yêu cầu một phương pháp tiếp cận riêng biệt để cân bằng giữa tốc độ xử lý và tài nguyên bộ nhớ.
Hiểu rõ thuật toán tìm kiếm là gì giúp lập trình viên lựa chọn đúng công cụ cho bài toán cụ thể. Việc sử dụng sai thuật toán trên tập dữ liệu hàng tỷ bản ghi có thể dẫn đến treo hệ thống hoặc lãng phí tài nguyên máy chủ nghiêm trọng.
Phân loại các nhóm thuật toán tìm kiếm phổ biến
Để nắm vững thuật toán tìm kiếm là gì, chúng ta cần phân loại chúng dựa trên cách thức truy cập dữ liệu. Có hai phương pháp tiếp tiếp cận chính thường gặp trong thực tế lập trình:
- Tìm kiếm trên dữ liệu chưa sắp xếp: Điển hình là tìm kiếm tuần tự, phù hợp với danh sách nhỏ hoặc thay đổi liên tục.
- Tìm kiếm trên dữ liệu đã sắp xếp: Bao gồm tìm kiếm nhị phân, tìm kiếm nội suy, mang lại hiệu suất vượt trội cho dữ liệu tĩnh.
Mỗi nhóm thuật toán có ưu nhược điểm riêng dựa trên đặc thù của bộ nhớ và CPU. Khi dữ liệu nằm trên RAM, tốc độ truy cập ngẫu nhiên nhanh thường ưu tiên các thuật toán chia để trị.
Thuật toán Tìm kiếm Tuần tự (Linear Search)
Tìm kiếm tuần tự là phương thức đơn giản nhất để trả lời câu hỏi thực thi thuật toán tìm kiếm là gì. Thuật toán này kiểm tra từng phần tử trong danh sách từ đầu đến cuối cho đến khi tìm thấy mục tiêu.
Nguyên lý hoạt động của Linear Search
Giả sử bạn có một dãy các hộp gỗ đóng kín. Mỗi hộp chứa một số tự nhiên ngẫu nhiên và không được sắp xếp theo thứ tự nào cả. Để tìm một số cụ thể, bạn buộc phải mở từng hộp một cách lần lượt.
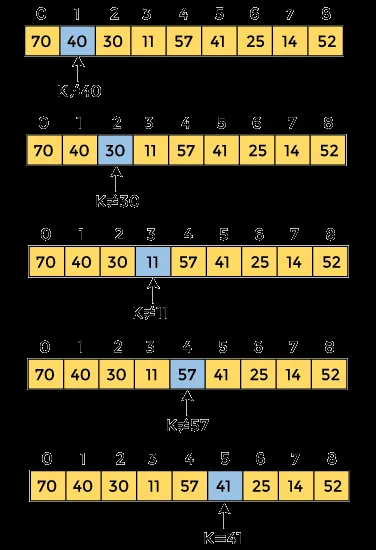
Cơ chế này tương ứng với vòng lặp đơn trong lập trình. Nếu phần tử nằm ở cuối danh sách hoặc không tồn tại, thuật toán phải duyệt qua toàn bộ $n$ phần tử.
Triển khai mã nguồn Linear Search chuẩn hóa
Dưới đây là phiên bản cài đặt bằng ngôn ngữ Python 3.10+ với đầy đủ Type Hinting và chú thích chuyên môn.
from typing import List, Optional def linear_search(arr: List[int], target: int) -> Optional[int]: """ Thực hiện tìm kiếm tuần tự trên mảng. Version: Python 3.10+ Time Complexity: O(n) Space Complexity: O(1) """ # Duyệt qua từng chỉ số và giá trị trong mảng for index in range(len(arr)): if arr[index] == target: # Trả về chỉ số ngay khi tìm thấy (Early Exit) return index # Trả về None nếu không tìm thấy sau khi duyệt hết mảng return None # Demo thực tế data = [70, 40, 30, 11, 7, 41, 25, 14, 52] search_target = 41 result = linear_search(data, search_target) print(f"Vị trí của {search_target} là: {result}") # Output mẫu: Vị trí của 41 là: 5Phân tích độ phức tạp và giới hạn
Trong khoa học máy tính, độ phức tạp của thuật toán tìm kiếm là gì được đo bằng ký hiệu Big O. Đối với Linear Search:
- Best Case: $O(1)$ khi phần tử nằm ngay vị trí đầu tiên.
- Worst Case: $O(n)$ khi phần tử ở cuối hoặc không có trong mảng.
- Average Case: $O(n/2)$, tương đương với $O(n)$.
Điểm yếu chí mạng của nó là hiệu suất giảm tuyến tính theo kích thước dữ liệu. Tuy nhiên, nó lại là thuật toán tối ưu khi làm việc với danh sách liên kết (Linked List) đơn lẻ do hạn chế về khả năng truy cập ngẫu nhiên.
Thuật toán Tìm kiếm Nhị phân (Binary Search)
Để giải quyết bài toán hiệu suất trên tập dữ liệu lớn, tìm kiếm nhị phân ra đời. Đây là minh chứng rõ nhất cho sức mạnh của tư duy “chia để trị” (Divide and Conquer) trong lập trình.
Điều kiện tiên quyết của Binary Search
Trước khi tìm hiểu cách triển khai thuật toán tìm kiếm là gì ở dạng nhị phân, bạn cần nhớ một quy tắc sắt đá: mảng đã sắp xếp là bắt buộc. Nếu dữ liệu đầu vào chưa được sắp xếp, kết quả trả về sẽ hoàn toàn sai lệch.
Cơ chế chia đôi không gian tìm kiếm
Thay vì dò từng bước, thuật toán nhảy thẳng vào vị trí giữa mảng. Nếu giá trị tại đó lớn hơn mục tiêu, chúng ta loại bỏ toàn bộ nửa phải. Nếu nhỏ hơn, chúng ta loại bỏ nửa trái.
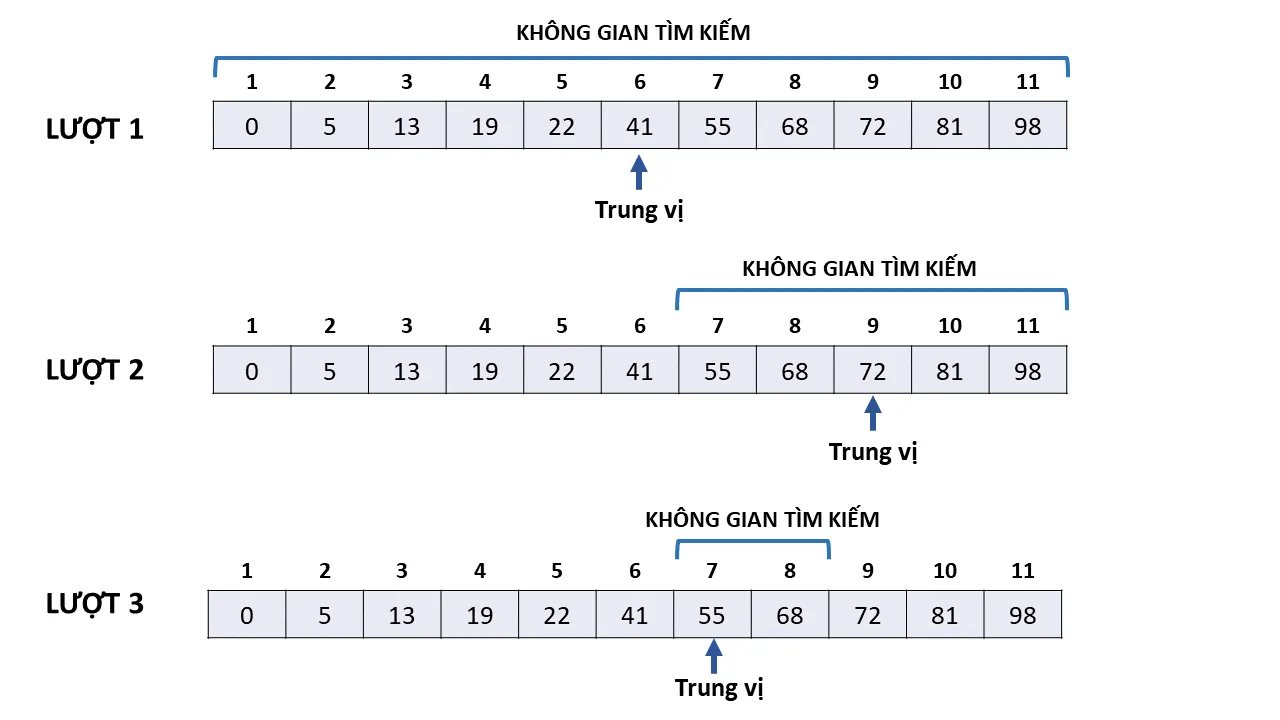
Quá trình này lặp lại liên tục, thu hẹp phạm vi tìm kiếm theo hàm logarit. Với 1 triệu phần tử, Linear Search cần tới 1 triệu bước, nhưng Binary Search chỉ cần tối đa khoảng 20 bước để tìm ra kết quả.
Mã nguồn C++17 tối ưu cho Binary Search
Trong thực tế, lỗi phổ biến nhất khi code Binary Search là tràn số (integer overflow) khi tính giá trị trung bình. Mã nguồn dưới đây xử lý triệt để vấn đề này.
#include #include #include / Thuật toán Tìm kiếm Nhị phân tối ưu Ngôn ngữ: C++17 Giải quyết lỗi tràn số (mid value overflow) / int binarySearch(const std::vector& arr, int target) { int left = 0; int right = static_cast(arr.size()) - 1; while (left <= right) { // Tránh lỗi (left + right) / 2 có thể gây tràn số int int mid = left + (right - left) / 2; if (arr[mid] == target) { return mid; // Tìm thấy mục tiêu } if (arr[mid] < target) { left = mid + 1; // Thu hẹp về phía bên phải } else { right = mid - 1; // Thu hẹp về phía bên trái } } return -1; // Không tìm thấy } int main() { // Mảng bắt buộc phải được sắp xếp trước khi tìm kiếm std::vector sortedData = {7, 11, 14, 25, 30, 41, 52, 70, 72, 88}; int target = 55; int result = binarySearch(sortedData, target); if (result != -1) { std::cout << "Phần tử được tìm thấy tại chỉ số: " << result << std::endl; } else { std::cout << "Không tìm thấy phần tử yêu cầu." << std::endl; } return 0; }Phân tích hiệu năng chuyên sâu
Độ phức tạp thời gian của Binary Search là $O(log n)$. Đây là một sự cải thiện kinh ngạc về mặt toán học. Theo tài liệu Introduction to Algorithms của Cormen et al., tốc độ này cho phép xử lý dữ liệu quy mô toàn cầu trong thời gian thực.
Tuy nhiên, chi phí bộ nhớ cần được cân nhắc nếu sử dụng đệ quy (Recursive Approach) thay vì vòng lặp (Iterative Approach). Đệ quy có thể dẫn đến lỗi Stack Overflow nếu độ sâu mảng quá lớn và trình biên dịch không tối ưu được Tail Call.
So sánh chi tiết hai thuật toán kinh điển
Khi được hỏi sự khác biệt cốt lõi của các thuật toán tìm kiếm là gì, chuyên gia thường dùng bảng so sánh dưới đây để định hướng chiến lược code.
| Tiêu chí | Tìm kiếm Tuần tự | Tìm kiếm Nhị phân |
|---|---|---|
| Độ phức tạp | $O(n)$ – Tuyến tính | $O(log n)$ – Logarit |
| Yêu cầu dữ liệu | Không cần sắp xếp | Phải là mảng đã sắp xếp |
| Cấu trúc dữ liệu | Mảng, Danh sách liên kết | Mảng truy cập ngẫu nhiên |
| Tính đơn giản | Rất cao | Trung bình |
| Sử dụng thực tế | Tập dữ liệu nhỏ, Cache-friendly | Tập dữ liệu lớn, Database Index |
Một điểm thú vị là Linear Search đôi khi nhanh hơn Binary Search trên các mảng cực nhỏ (dưới 16-32 phần tử). Điều này do tính chất Cache Locality của CPU; việc duyệt tuần tự giúp tận dụng tối đa dữ liệu đã được nạp vào L1 Cache.
Các lỗi thường gặp khi triển khai thuật toán
Hiểu lý thuyết thuật toán tìm kiếm là gì là chưa đủ, bạn cần nhận diện được các “bẫy” trong quá trình thực thi:
- Off-by-one Error: Lỗi tính toán chỉ số biên
leftvàrightdẫn đến vòng lặp vô tận. - Lỗi sắp xếp: Quên sắp xếp dữ liệu trước khi dùng Binary Search.
- Kiểu dữ liệu: So sánh số thực (floating point) bằng toán tử
==thay vì dùng một khoảng sai số (epsilon). - Hệ quả của mảng động: Trong một số ngôn ngữ, việc truyền mảng vào hàm đệ quy mà không dùng tham chiếu (reference) có thể tạo ra bản sao mảng, làm tăng độ phức tạp không gian lên $O(n log n)$.
Ứng dụng thực tiễn của thuật toán tìm kiếm là gì?
Trong phát triển phần mềm, ứng dụng của thuật toán tìm kiếm là gì hiện diện ở mọi nơi. Khi bạn gõ một từ khóa trên thanh tìm kiếm của hệ điều hành, các thuật toán biến thể của tìm kiếm nhị phân như B-Tree hoặc LSM-Tree đang hoạt động phía dưới.
Trong xử lý văn bản, việc tìm một từ trong từ điển điện tử sử dụng cơ chế chia đôi không gian để đạt tốc độ tức thì. Các hệ quản trị cơ sở dữ liệu như MySQL hay PostgreSQL sử dụng “Index” – thực chất là một cấu trúc dữ liệu được thiết kế để tối ưu hóa thuật toán tìm kiếm là gì – giúp truy vấn hàng triệu dòng dữ liệu trong mili giây.
Tối ưu hóa nâng cao: Tìm kiếm nội suy (Interpolation Search)
Nếu mảng không chỉ đã sắp xếp mà còn có giá trị phân phối đều, chúng ta có thể cải tiến Binary Search thành Interpolation Search. Thay vì luôn chọn vị trí ở giữa ($mid$), thuật toán này ước lượng vị trí dựa trên giá trị của mục tiêu, giống như cách chúng ta tìm chữ “T” ở gần cuối cuốn từ điển.
Công thức tính vị trí: pos = low + [ (target - arr[low]) (high - low) / (arr[high] - arr[low]) ]
Độ phức tạp trung bình của nó đạt tới $O(log(log n))$, một mức hiệu suất gần như tuyệt đối cho các hệ thống Big Data phân phối đều.
Lời khuyên cho lập trình viên khi lựa chọn
Để áp dụng thành công thuật toán tìm kiếm là gì, hãy luôn bắt đầu bằng việc phân tích đặc điểm dữ liệu. Nếu dữ liệu của bạn thường xuyên thay đổi (chèn/xóa liên tục), chi phí để duy trì mảng sắp xếp cho Binary Search có thể lớn hơn lợi ích nó mang lại. Trong trường hợp đó, các cấu trúc dữ liệu như Hash Map (độ phức tạp trung bình $O(1)$) hoặc Binary Search Tree cân bằng sẽ là lựa chọn thay thế thông minh hơn.
Việc nắm vững kiến thức thuật toán tìm kiếm là gì không chỉ giúp bạn vượt qua các kỳ phỏng vấn kỹ thuật mà còn là nền tảng để xây dựng những ứng dụng phần mềm có khả năng mở rộng cao. Hãy luôn thực hành viết code thông qua các bài tập Python nâng cao và phân tích Big O để rèn luyện tư duy tối ưu hóa của một lập trình viên senior.
Hy vọng bài viết này đã giúp bạn hiểu rõ bản chất thuật toán tìm kiếm là gì và cách áp dụng chúng vào dự án thực tế thông qua các ví dụ mã nguồn chi tiết. Để nâng cao kỹ năng, hãy thử triển khai thêm các biến thể khác như Jump Search hoặc Exponential Search trên bộ dữ liệu lớn tại thuviencntt.com.
Cập nhật lần cuối 04/03/2026 by Hiếu IT