Trong lĩnh vực xây dựng Mạng thần kinh, việc lựa chọn bộ tối ưu đóng vai trò then chốt đến tốc độ hội tụ của mô hình. thuật toán tối ưu adam (Adaptive Moment Estimation) đã nhanh chóng trở thành tiêu chuẩn vàng nhờ khả năng kết hợp ưu điểm vượt trội của Momentum và RMSprop. Bằng cách tính toán tốc độ học thích nghi cho từng tham số riêng biệt, phương pháp này xử lý hiệu quả các bài toán có dữ liệu thưa thớt hoặc nhiễu lớn trong Học máy.
Nền tảng phát triển của các bộ tối ưu hóa hiện đại
Để hiểu rõ tại sao thuật toán tối ưu adam lại mang lại hiệu quả cao đến vậy, chúng ta cần nhìn lại lộ trình tiến hóa của kỹ thuật Gradient Descent. Ban đầu, Stochastic Gradient Descent (SGD) cập nhật trọng số bằng một hằng số Learning Rate duy nhất cho toàn bộ tham số. Điều này gây khó khăn khi dữ liệu có sự biến thiên lớn về biên độ giữa các chiều (feature).
Sau đó, Momentum được giới thiệu để giúp vượt qua các điểm cực tiểu địa phương (local minima) bằng cách tích lũy “vận tốc” từ các bước trước đó. Tuy nhiên, các kỹ thuật này vẫn thiếu tính linh hoạt trong việc tự điều chỉnh bước nhảy cho từng tham số cụ thể. Các nghiên cứu tiếp theo như Adagrad và RMSprop đã giải quyết vấn đề này bằng cách chia Learning Rate cho trung bình bình phương của các đạo hàm trước đó, nhưng mỗi loại lại có những hạn chế về việc làm giảm tốc độ học quá nhanh hoặc thiếu đi sự ổn định của gia tốc.
Cơ chế hoạt động chi tiết của thuật toán tối ưu adam
Về cốt lõi, thuật toán tối ưu adam mô phỏng một quả cầu nặng có ma sát khi lăn xuống dốc. Nó không chỉ quan tâm đến độ dốc hiện tại mà còn lưu giữ thông tin về quán tính (First Moment) và sự biến động của độ dốc (Second Moment). Điều này giúp thuật toán duy trì sự ổn định ngay cả khi bề mặt hàm mất mát có dạng “yên ngựa” hoặc các thung lũng hẹp, nơi các bộ tối ưu thông thường dễ bị kẹt.
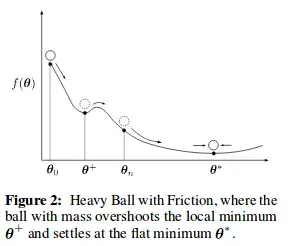
Công thức trên cho thấy cách Adam tính toán trung bình động của các đạo hàm ($m_t$) và trung bình động của bình phương đạo hàm ($v_t$). Hệ số $beta_1$ (thường là 0.9) kiểm soát mức độ ảnh hưởng của Momentum, trong khi $beta_2$ (thường là 0.999) kiểm soát phần RMSprop. Sự kết hợp này tạo ra một hiệu ứng mà thuật toán gọi là “Heavy Ball with Friction” (HBF), cho phép nén các dao động không cần thiết và tập trung vào hướng hội tụ nhanh nhất.
Vai trò của Bias Correction trong giai đoạn khởi đầu
Một trong những điểm tinh tế nhất của thuật toán tối ưu adam chính là cơ chế hiệu chỉnh sai số (Bias Correction). Trong những vòng lặp đầu tiên, các giá trị $m_t$ và $v_t$ thường được khởi tạo bằng 0, dẫn đến việc chúng bị kéo về gần gốc tọa độ, đặc biệt khi các hệ số phân rã $beta_1, beta_2$ gần bằng 1.
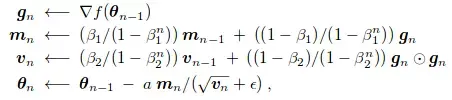
Để khắc phục hiện tượng này, Adam sử dụng các giá trị $hat{m}_t$ và $hat{v}_t$ đã được hiệu chỉnh để đảm bảo rằng trong giai đoạn đầu, các bước cập nhật trọng số không bị quá nhỏ. Nếu thiếu bước này, mô hình sẽ mất rất nhiều thời gian chỉ để “thoát ra” khỏi trạng thái khởi tạo ban đầu, làm giảm đáng kể hiệu năng tổng thể của quá trình Tối ưu hóa.
Triển khai thuật toán tối ưu adam với Python và NumPy
Dưới đây là mã nguồn triển khai Adam từ đầu bằng ngôn ngữ Python 3.10+. Việc hiểu cách code thủ công thay vì dùng thư viện mức cao như PyTorch giúp lập trình viên kiểm soát tốt hơn các Hyperparameters trong dự án thực tế.
import numpy as np
class AdamOptimizer:
"""
Triển khai thuật toán tối ưu adam (Python 3.10+)
Dựa trên paper của Kingma & Ba (2014)
"""
def __init__(self, learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8):
self.lr = learning_rate
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.m = None # First moment
self.v = None # Second moment
self.t = 0 # Time step
def update(self, w, grad_w):
"""
Input: w (weights), grad_w (gradients)
Output: Updated weights
Complexity: Time O(N), Space O(N) với N là số lượng tham số
"""
if self.m is None:
self.m = np.zeros_like(w)
self.v = np.zeros_like(w)
self.t += 1
# Cập nhật moment bậc 1 (Momentum)
self.m = self.beta1 self.m + (1 - self.beta1) grad_w
# Cập nhật moment bậc 2 (RMSprop part)
self.v = self.beta2 self.v + (1 - self.beta2) (grad_w2)
# Hiệu chỉnh sai số (Bias correction)
m_hat = self.m / (1 - self.beta1self.t)
v_hat = self.v / (1 - self.beta2self.t)
# Cập nhật trọng số
w_new = w - self.lr m_hat / (np.sqrt(v_hat) + self.epsilon)
return w_new
# Ví dụ minh họa sử dụng thực tế
if __name__ == "__main__":
# Giả thuyết một bộ trọng số ngẫu nhiên
weights = np.array([0.5, -0.2, 0.1])
# Giả thuyết gradient tính được từ backpropagation
gradients = np.array([0.01, 0.05, -0.02])
optimizer = AdamOptimizer(learning_rate=0.1)
for epoch in range(5):
weights = optimizer.update(weights, gradients)
print(f"Epoch {epoch+1}: Weights = {weights}")Trong thực tế, độ phức tạp về thời gian là $O(N)$ cho mỗi bước cập nhật, trong đó $N$ là tổng số lượng tham số trong Neural Networks. Về bộ nhớ, Adam yêu cầu gấp 3 lần so với SGD thuần túy vì phải lưu giữ hai trạng thái $m$ và $v$ cho mỗi trọng số.
So sánh hiệu năng hội tụ giữa Adam và các bộ tối ưu khác
Khi so sánh trên các bề mặt hàm mất mát phức tạp, thuật toán tối ưu adam thường cho thấy khả năng vượt qua các vùng phẳng nhanh hơn hẳn so với SGD truyền thống.
Ảnh trên minh họa sự khác biệt về tốc độ hội tụ. Trong khi SGD có thể mất nhiều thời gian để dao động quanh các thung lũng, Adam tận dụng Momentum để đẩy nhanh tốc độ ở các hướng có đạo hàm nhất quán. Điều này cực kỳ quan trọng đối với các kiến trúc Mạng thần kinh sâu, nơi lỗi Gradient biến mất (Vanishing Gradient) là một vấn đề nhức nhối.
Hình ảnh này cho thấy cách Adam điều hướng trên bề mặt lỗi. Nhờ có moment bậc hai, nó tự động giảm tốc độ khi gần đến cực tiểu toàn cục, giúp tránh hiện tượng “vượt quá” (overshooting) thường thấy ở các phương pháp có tốc độ học cố định.
| Đặc tính | SGD | Momentum | RMSprop | Adam |
|---|---|---|---|---|
| Tốc độ học | Cố định | Cố định | Thích nghi | Thích nghi |
| Quán tính | Không | Có | Không | Có |
| Độ ổn định | Thấp | Trung bình | Cao | Rất cao |
| Bộ nhớ | Thấp | Trung bình | Trung bình | Cao |
Những lỗi thường gặp và kinh nghiệm debug trong dự án thực tế
Dù được coi là bộ tối ưu “cắm và chạy”, việc sử dụng thuật toán tối ưu adam vẫn tiềm ẩn một số cạm bẫy mà các lập trình viên Senior cần lưu ý. Lỗi phổ biến nhất là đặt Learning Rate quá lớn ($alpha > 0.1$) với hy vọng mô hình hội tụ nhanh hơn, nhưng thực tế điều này thường khiến mô hình bị phân kỳ (Divergence) hoặc kẹt ở các điểm cực tiểu kém chất lượng.
Thứ hai là vấn đề về khả năng tổng quát hóa (Generalization). Một số nghiên cứu đã chỉ ra rằng trong một số bài toán Computer Vision, SGD với Momentum có thể tìm thấy các cực tiểu “phẳng” hơn, giúp mô hình đạt độ chính xác cao hơn trên tập Test so với Adam. Vì vậy, một tip quan trọng là: hãy bắt đầu với Adam để Prototype nhanh, nhưng khi cần tối ưu hóa đến từng 0.1% độ chính xác cuối cùng, hãy cân nhắc chuyển sang SGD để tinh chỉnh.
Khi debug, nếu bạn thấy Loss không giảm hoặc nhảy loạn xạ ngay từ đầu, hãy kiểm tra lại giá trị $epsilon$ (epsilon). Trong các bài toán sử dụng độ chính xác số thực thấp (float16), giá trị mặc định $1e-8$ có thể quá nhỏ gây lỗi tràn số, hãy thử tăng lên $1e-7$ hoặc $1e-6$ để ổn định hóa quá trình tính toán.
Phân tích độ phức tạp thuật toán (Big O Analysis)
Dưới góc nhìn của một kỹ sư phần mềm, việc đánh giá tài nguyên là bắt buộc. Đối với mỗi tham số $theta$ trong mạng:
- Time Complexity: $O(1)$ cho mỗi tham số trên mỗi bước lặp. Tổng thể là $O(N)$ với $N$ là số tham số. Phép toán chủ yếu là cộng, nhân và căn bậc hai, vốn cực kỳ rẻ trên GPU.
- Space Complexity: $O(N)$ thêm vào để lưu trữ các trạng thái gradient. Nếu mạng có 100 triệu tham số, bạn cần thêm khoảng 800MB VRAM (nếu dùng single precision float32) chỉ để phục vụ bộ tối ưu này.

Sơ đồ tổng quát trên nhắc lại rằng dù phức tạp hơn về mặt toán học, cấu trúc của Adam vẫn tuân thủ chặt chẽ quy trình của hệ thống học có giám sát. Việc tích hợp Adam vào các framework như TensorFlow hay PyTorch thực chất là việc vector hóa các phép toán này để tận dụng sức mạnh tính toán song song.
Ứng dụng thực tế và hướng phát triển tương lai
Hiện nay, thuật toán tối ưu adam là lựa chọn mặc định cho hầu hết các bài toán xử lý ngôn ngữ tự nhiên (NLP) với kiến trúc Transformer và các bài toán Generative AI. Khả năng xử lý tốt các gradient thưa thớt (sparse gradients) giúp nó trở nên vô đối khi huấn luyện các mô hình ngôn ngữ lớn (LLM), nơi mà nhiều từ vựng hiếm khi xuất hiện trong batch.
Tuy nhiên, cộng đồng nghiên cứu cũng đã cho ra đời các biến thể như AdamW (sửa lỗi Weight Decay), Adafactor (giảm bộ nhớ) hay RAdam (Rectified Adam) nhằm cải thiện sự ổn định ở giai đoạn đầu huấn luyện. Việc nắm vững nguyên lý gốc của Adam sẽ giúp bạn dễ dàng nắm bắt các biến thể nâng cao này trong tương lai.
Hy vọng bài phân tích chuyên sâu này từ Thư Viện CNTT đã giúp bạn hiểu rõ bản chất và cách vận hành của thuật toán tối ưu adam. Để nâng cao kỹ năng, bạn nên thử thay đổi các giá trị Hyperparameters trong code mẫu và quan sát sự thay đổi của đồ thị hàm mất mát.
Tham khảo:
- Kingma, D. P., & Ba, J. (2014). Adam: A Method for Stochastic Optimization. arXiv preprint arXiv:1412.6980.
- PyTorch Documentation: torch.optim.Adam.
- Andrej Karpathy: CS231n Convolutional Neural Networks for Visual Recognition.
Cập nhật lần cuối 02/03/2026 by Hiếu IT